Classification Machine Learning คืออะไร? คู่มือฉบับสมบูรณ์ 2026 สำหรับทุกคน

บทนำ: Classification Machine Learning คืออะไร?
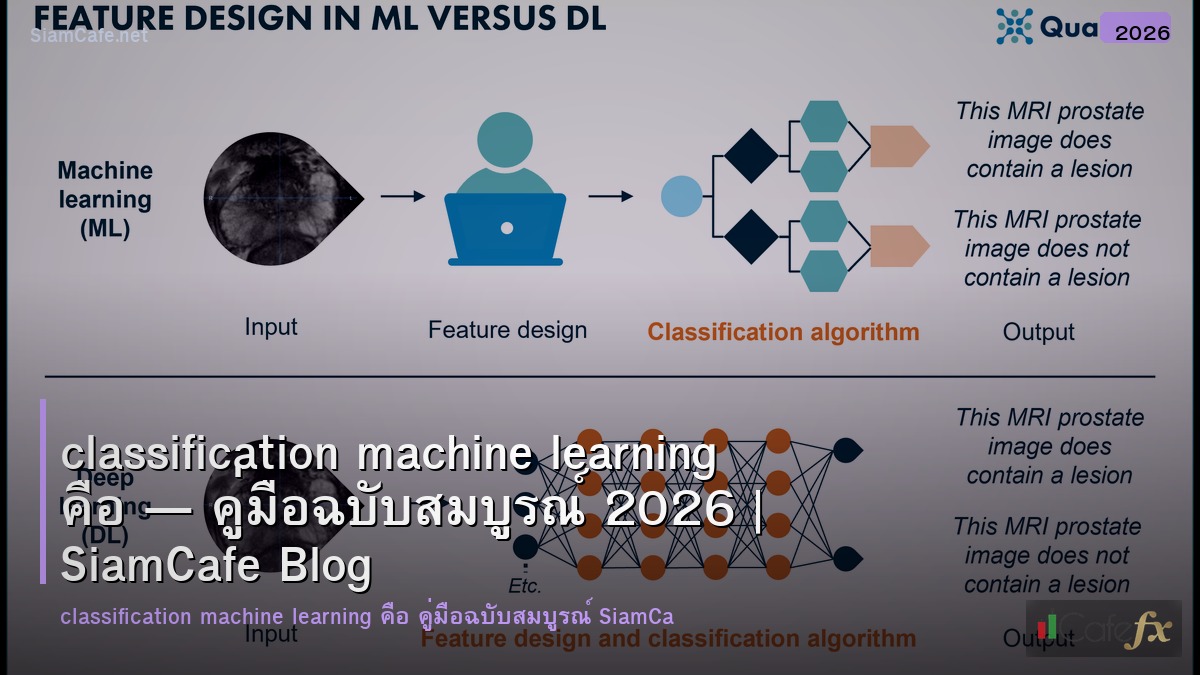
Classification Machine Learning คือสาขาหนึ่งของ Machine Learning ที่มุ่งเน้นการจัดหมวดหมู่ข้อมูลให้อยู่ในกลุ่มที่กำหนดล่วงหน้า ตัวอย่างเช่น การระบุว่าอีเมลเป็นอีเมลขยะ (spam) หรือไม่ เป็นการจัดหมวดหมู่ข้อมูลอีเมลให้อยู่ในกลุ่ม 'spam' หรือ 'not spam'
ประเภทของ Classification
1. Binary Classification
เป็นการจัดหมวดหมู่ข้อมูลให้อยู่ในกลุ่มใดกลุ่มหนึ่งเพียงกลุ่มเดียว ตัวอย่างเช่น การตรวจจับอีเมลขยะ (spam) หรือการวินิจฉัยว่าผู้ป่วยมีโรคหรือไม่
เนื้อหาเกี่ยวข้อง — อ่านต่อ: WordPress WooCommerce Log Management ELK —
2. Multi-Class Classification
เป็นการจัดหมวดหมู่ข้อมูลให้อยู่ในกลุ่มที่มากกว่าสองกลุ่ม ตัวอย่างเช่น การจัดประเภทของดอกไม้เป็นกลุ่ม 'iris setosa', 'iris versicolor', หรือ 'iris virginica'
3. Multi-Label Classification
เป็นการจัดหมวดหมู่ข้อมูลให้อยู่ในกลุ่มได้หลายกลุ่มพร้อมกัน ตัวอย่างเช่น การระบุว่าภาพถ่ายมีดอกไม้ ภูเขา และทะเลอยู่ในภาพหรือไม่
แนะนำเพิ่มเติม — ระบบเทรดของ iCafeForex
เนื้อหาเกี่ยวข้อง — บทความที่เกี่ยวข้อง: Python Rich Stream Processing
วิธีการที่ใช้ใน Classification
- Decision Trees: สร้างต้นไม้โครงสร้างเพื่อตัดสินใจว่าข้อมูลควรอยู่ในกลุ่มใด
- Logistic Regression: ใช้สมการทางคณิตศาสตร์เพื่อคาดการณ์ความน่าจะเป็นของข้อมูลในกลุ่มที่กำหนด
- Support Vector Machines (SVM): สร้างเส้นแบ่งระหว่างกลุ่มข้อมูลเพื่อแยกแยะข้อมูลในแต่ละกลุ่ม
- Neural Networks: จำลองการทำงานของสมองมนุษย์เพื่อเรียนรู้รูปแบบของข้อมูลและจัดหมวดหมู่อย่างแม่นยำ
การใช้งานจริงในชีวิตประจำวัน
- การตรวจจับอีเมลขยะ (Spam Detection): ระบบอีเมลใช้ classification เพื่อแยกแยะอีเมลที่ไม่พึงประสงค์ออกจากอีเมลที่เป็นประโยชน์
- การวินิจฉัยโรค: แพทย์ใช้ classification เพื่อวินิจฉัยว่าผู้ป่วยมีโรคหรือไม่จากผลการตรวจทางการแพทย์
- การแนะนำสินค้า: ระบบ e-commerce ใช้ classification เพื่อแนะนำสินค้าที่น่าสนใจให้กับลูกค้า
- การตรวจสอบเครดิต: ธนาคารใช้ classification เพื่อประเมินความเสี่ยงในการให้สินเชื่อกับลูกค้า
ประโยชน์และความท้าทายของ Classification Machine Learning
ประโยชน์:
- ช่วยให้การตัดสินใจมีความแม่นยำมากขึ้น
- ประหยัดเวลาและทรัพยากรในการวิเคราะห์ข้อมูล
- สามารถนำไปประยุกต์ใช้งานได้หลากหลาย
ความท้าทาย:
- ต้องมีข้อมูลที่มีคุณภาพสูงเพื่อฝึกโมเดล
- การเลือกโมเดลที่เหมาะสมกับข้อมูลเป็นเรื่องที่ซับซ้อน
- ต้องระวัง bias ที่อาจเกิดขึ้นจากข้อมูล
แนวโน้มในอนาคตของ Classification Machine Learning ปี 2026
ในปี 2026 การพัฒนาการของ Classification Machine Learning จะมุ่งเน้นไปที่การปรับปรุงความแม่นยำของโมเดล การลด bias ที่อาจเกิดขึ้นจากข้อมูล และการประยุกต์ใช้งานในด้านใหม่ๆ เช่น การแพทย์เฉพาะบุคคล (personalized medicine) และการพัฒนา AI ที่สามารถเข้าใจอารมณ์และความต้องการของมนุษย์ได้ดียิ่งขึ้น
เนื้อหาเกี่ยวข้อง — ทำความเข้าใจ MLflow Experiment Architecture Design Pattern
คำถามที่พบบ่อย (FAQ)
-
Q1: ความแตกต่างระหว่าง Classification กับ Regression คืออะไร?
A1: Classification เป็นการจัดหมวดหมู่ข้อมูลให้อยู่ในกลุ่มที่กำหนดล่วงหน้า ในขณะที่ Regression เป็นการคาดการณ์ค่าต่อเนื่อง (continuous value) เช่น การคาดการณ์ราคาหุ้น
แนะนำเพิ่มเติม — XM Signal
-
Q2: ควรเลือกโมเดล Classification แบบไหนสำหรับข้อมูลของฉัน?
A2: การเลือกโมเดล Classification ขึ้นอยู่กับลักษณะของข้อมูลและปัญหาที่ต้องการแก้ไข ควรพิจารณาจากประเภทของข้อมูล (structured/unstructured) จำนวนข้อมูล และความซับซ้อนของปัญหา
เนื้อหาเกี่ยวข้อง — อ่านต่อ: Crowdsec IPS GreenOps Sustainability —
-
Q3: การใช้ Classification Machine Learning มีข้อดีและข้อเสียอะไรบ้าง?
A3: ข้อดีคือช่วยให้การตัดสินใจมีความแม่นยำและประหยัดเวลา ข้อเสียคือต้องมีข้อมูลที่มีคุณภาพสูงและต้องระวัง bias ที่อาจเกิดขึ้นจากข้อมูล





