stable diffusion ui — วิธีตั้งค่าและใช้งานจริงพร้อมตัวอย่าง
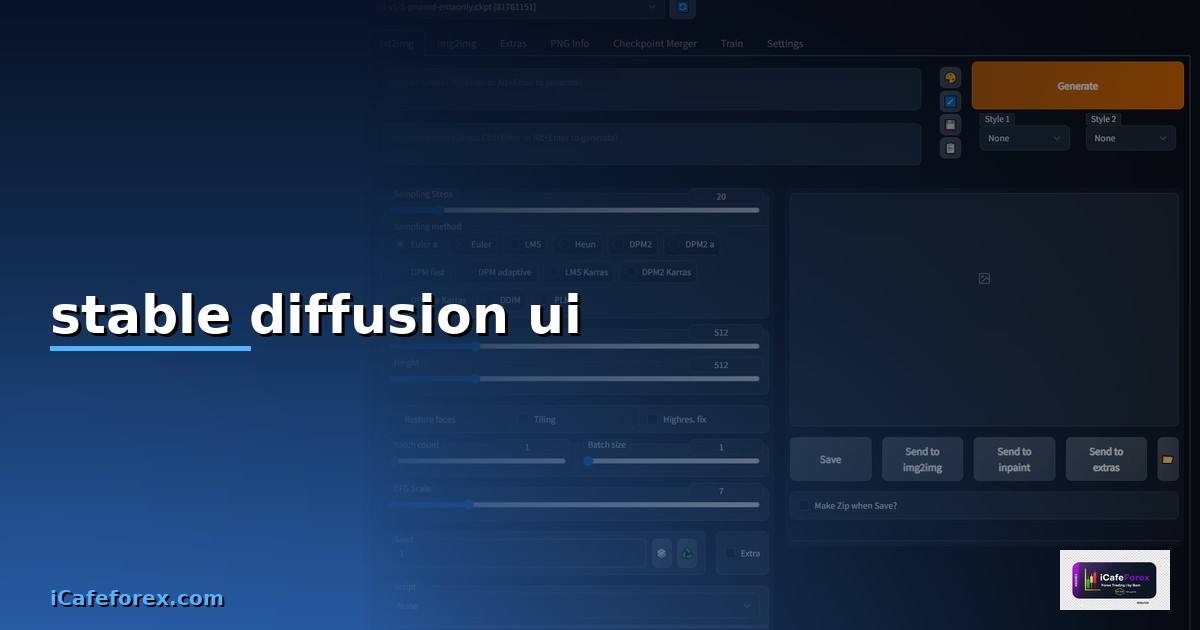
stable diffusion ui คืออะไร — อธิบายแบบเจาะลึก

stable diffusion ui เป็นหัวข้อที่มีความสำคัญอย่างยิ่งในวงการ IT สมัยใหม่โดยเฉพาะในยุคที่ระบบ Infrastructure มีความซับซ้อนมากขึ้นเรื่อยๆการทำความเข้าใจเรื่องนี้อย่างถ่องแท้จะช่วยให้ผู้ดูแลระบบและนักพัฒนาสามารถทำงานได้อย่างมีประสิทธิภาพมากขึ้น
ในบทความนี้จะอธิบายรายละเอียดเกี่ยวกับ stable diffusion ui ตั้งแต่พื้นฐานไปจนถึงการนำไปใช้งานจริงพร้อมตัวอย่างคำสั่งและ configuration ที่ใช้ได้ทันทีเนื้อหาครอบคลุมทั้งภาคทฤษฎีและภาคปฏิบัติเหมาะสำหรับผู้ที่ต้องการเข้าใจ stable diffusion ui อย่างลึกซึ้ง
อ่านเพิ่ม: RAG Architecture Micro-segmentation — วิธีตั้งค่าและใช้งานจร · อ่านเพิ่ม: Stable Diffusion ComfyUI Backup Recovery Strategy — วิธีตั้ง · อ่านเพิ่ม: Real GDP คืออะไร — วิธีตั้งค่าและใช้งานจริงพร้อมตัวอย่าง
สิ่งสำคัญที่ต้องเข้าใจก่อนเริ่มต้นคือ stable diffusion ui ไม่ได้เป็นเพียงแค่เครื่องมือหรือเทคนิคเดียวแต่เป็นชุดของแนวคิดและ best practices ที่ทำงานร่วมกันเพื่อให้ได้ผลลัพธ์ที่ดีที่สุดการเรียนรู้อย่างเป็นระบบจะช่วยให้เข้าใจภาพรวมและสามารถนำไปประยุกต์ใช้ในสถานการณ์ต่างๆได้อย่างมีประสิทธิภาพ
stable diffusion ui เป็นพื้นฐานสำคัญที่ทุกองค์กรควรให้ความสำคัญเพราะส่งผลโดยตรงต่อ performance, security และ reliability ของระบบทั้งหมด
ทำไม stable diffusion ui ถึงสำคัญในยุคปัจจุบัน
ในปัจจุบันองค์กรต่างๆต้องรับมือกับความท้าทายหลายด้านไม่ว่าจะเป็นการ scale ระบบให้รองรับผู้ใช้งานจำนวนมากการรักษาความปลอดภัยของข้อมูลหรือการลดต้นทุนในการดำเนินงาน stable diffusion ui เข้ามาตอบโจทย์เหล่านี้ได้อย่างมีประสิทธิภาพ
เหตุผลหลักที่ทำให้ stable diffusion ui มีความสำคัญ:
เนื้อหาเกี่ยวข้อง — แนะนำให้อ่าน ModSecurity WAF Batch Processing Pipeline
- เพิ่มประสิทธิภาพการทำงาน: ช่วยลดเวลาในการทำงานซ้ำๆและลดความผิดพลาดที่เกิดจากการทำงานแบบ manual ทำให้ทีมสามารถโฟกัสกับงานที่มีมูลค่าสูงกว่า
- ลดความเสี่ยงด้านต่างๆ: การมีระบบที่เป็นมาตรฐานช่วยลดโอกาสเกิดปัญหาที่ไม่คาดคิดและเมื่อเกิดปัญหาก็สามารถแก้ไขได้รวดเร็ว
- รองรับการขยายตัว: เมื่อระบบต้องรองรับ workload ที่เพิ่มขึ้น stable diffusion ui ช่วยให้ scale ได้อย่างราบรื่นไม่ต้องรื้อระบบใหม่ทั้งหมด
- ประหยัดค่าใช้จ่าย: การใช้ทรัพยากรอย่างมีประสิทธิภาพช่วยลดค่าใช้จ่ายด้าน infrastructure ได้อย่างมีนัยสำคัญ
- เพิ่มความน่าเชื่อถือ: ระบบที่ออกแบบมาอย่างดีมี uptime สูงผู้ใช้งานมีความพึงพอใจมากขึ้นและธุรกิจดำเนินต่อไปได้อย่างราบรื่น
จากประสบการณ์ของผู้เขียนในวงการ IT กว่า 30 ปี stable diffusion ui เป็นหนึ่งในหัวข้อที่ผู้เชี่ยวชาญด้าน IT ทุกคนควรทำความเข้าใจโดยเฉพาะในยุคที่ Cloud Computing และ DevOps กลายเป็นมาตรฐานของอุตสาหกรรมไปแล้ว
วิธีตั้งค่า stable diffusion ui — ขั้นตอนปฏิบัติจริง
มาดูขั้นตอนการตั้งค่าและใช้งานจริงกันเริ่มจากการเตรียม environment ให้พร้อมก่อนจากนั้นจะแสดงตัวอย่าง configuration ที่ใช้งานได้จริงในระบบ production
LoRA Fine-tuning
จากตัวอย่างข้างต้นจะเห็นว่าการตั้งค่าไม่ได้ยุ่งยากเพียงทำตามขั้นตอนและปรับค่า parameter ให้เหมาะกับ environment ของตัวเองสิ่งสำคัญคือต้องทดสอบใน staging environment ก่อน deploy ขึ้น production เสมอ
แนะนำเพิ่มเติม — XM Signal
ข้อควรระวังที่สำคัญ:
- ตรวจสอบ compatibility กับ version ของ OS และ dependencies ที่ใช้งานอยู่ก่อนทำการเปลี่ยนแปลง
- ทำ backup ข้อมูลและ configuration ที่สำคัญทุกครั้งก่อนแก้ไข
- ใช้ version control เช่น Git สำหรับไฟล์ configuration ทุกไฟล์เพื่อ track changes
- มี rollback plan พร้อมเสมอในกรณีที่เกิดปัญหาหลังจาก deploy
การตั้งค่าขั้นสูงและ Best Practices
เมื่อเข้าใจพื้นฐานแล้วมาดูการตั้งค่าขั้นสูงที่จะช่วยให้ระบบทำงานได้ดียิ่งขึ้นส่วันนี้ี้ครอบคลุม best practices ที่ผู้เชี่ยวชาญในวงการแนะนำ
RAG pipeline
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import DirectoryLoader, TextLoader
from langchain.chains import RetrievalQA
from langchain.llms import Ollama
loader = DirectoryLoader('./docs', glob='**/*.md', loader_cls=TextLoader)
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = splitter.split_documents(docs)
embeddings = HuggingFaceEmbeddings(model_name='intfloat/multilingual-e5-base')
vectorstore = FAISS.from_documents(chunks, embeddings)
vectorstore.save_local('./faiss_index')
llm = Ollama(model='llama2', temperature=0.1)
qa = RetrievalQA.from_chain_type(llm=llm, chain_type='stuff',
retriever=vectorstore.as_retriever(search_kwargs={'k': 5}),
return_source_documents=True)
result = qa({'query': 'How to configure SSL?'})
print(result['result'])การตั้งค่าขั้นสูงเหล่านี้ช่วยเพิ่ม performance และ security ให้กับระบบอย่างมากสิ่งสำคัญคือต้องเข้าใจว่าแต่ละ parameter มีผลอย่างไรก่อนปรับเปลี่ยนค่า
เนื้อหาเกี่ยวข้อง — อ่านต่อ: Soda Data Quality สำหรับมือใหม่ Step by Step
Best practices ที่ควรปฏิบัติตาม:
- Principle of Least Privilege: ให้สิทธิ์เฉพาะที่จำเป็นเท่านั้นไม่ว่าจะเป็น user permissions, network access หรือ API scopes ลด attack surface ให้เหลือน้อยที่สุด
- Defense in Depth: มีหลายชั้นของการป้องกันไม่พึ่งพา security layer เดียวถ้าชั้นหนึ่งถูกเจาะยังมีชั้นอื่นรองรับ
- Automation First: automate ทุกอย่างที่ทำได้เพื่อลด human error และเพิ่มความเร็วในการ deploy และ respond ต่อปัญหา
- Monitor Everything: ติดตั้ง monitoring และ alerting ที่ครอบคลุมเพื่อตรวจจับปัญหาก่อนที่จะส่งผลกระทบต่อผู้ใช้งาน
- Document Everything: เขียน documentation สำหรับทุก configuration change เพื่อให้ทีมสามารถดูแลระบบต่อได้อย่างราบรื่น
การแก้ปัญหาและ Troubleshooting
แม้จะตั้งค่าอย่างถูกต้องแล้วก็ยังอาจพบปัญหาได้ในการใช้งานจริงส่วันนี้ี้จะรวบรวมปัญหาที่พบบ่อยพร้อมวิธีแก้ไขที่ทดสอบแล้วว่าได้ผลจริง
ML Pipeline with scikit-learn

เมื่อพบปัญหาสิ่งแรกที่ควรทำคือตรวจสอบ log files เพราะข้อมูลส่วนใหญ่ที่ต้องการจะอยู่ใน log จากนั้นค่อยๆ isolate ปัญหาโดยตรวจสอบทีละส่วนจากล่างขึ้นบน
ขั้นตอนการ troubleshoot ที่แนะนำ:
แนะนำเพิ่มเติม — SiamCafeBook
- ตรวจสอบ log files: ดู error messages ใน system logs, application logs และ service-specific logs ค้นหา keyword ที่เกี่ยวข้องกับปัญหา
- ตรวจสอบ connectivity: ใช้ ping, telnet, curl หรือ nc ทดสอบการเชื่อมต่อระหว่าง services แต่ละตัว
- ตรวจสอบ resource usage: ดู CPU, memory, disk และ network usage ว่ามี bottleneck ที่ไหนหรือไม่ใช้ top, htop, iostat, netstat
- ตรวจสอบ configuration: เปรียบเทียบ config ปัจจุบันกับ config ที่ทำงานได้ปกติครั้งล่าสุดดูว่ามีอะไรเปลี่ยนแปลง
- ทดสอบทีละส่วน: แยก component ออกทดสอบทีละตัวเพื่อ isolate จุดที่มีปัญหาให้ชัดเจน
การเก็บ log อย่างเป็นระบบและมี monitoring ที่ดีจะช่วยลดเวลาในการ troubleshoot ลงได้อย่างมากควรตั้ง alert สำหรับเหตุการณ์ผิดปกติเพื่อตรวจพบและแก้ไขปัญหาก่อนส่งผลกระทบต่อ service ที่ให้บริการอยู่
เปรียบเทียบและเลือกใช้ stable diffusion ui
การเลือกใช้เครื่องมือและเทคโนโลยีที่เหมาะสมเป็นสิ่งสำคัญต้องพิจารณาหลายปัจจัยรวมถึง use case, scale, budget และ team expertise
เนื้อหาเกี่ยวข้อง — MySQL InnoDB Tuning Community Building
| เกณฑ์ | ข้อดี | ข้อจำกัด |
|---|---|---|
| ความง่ายในการตั้งค่า | มี documentation ครบถ้วนและ community ใหญ่ | อาจต้องใช้เวลาเรียนรู้ในช่วงแรก |
| Performance | รองรับ high throughput ได้ดีเยี่ยม | ต้อง tune ค่า parameter ตาม workload |
| Security | มี security features ครบถ้วนตามมาตรฐาน | ต้องอัปเดต patch อย่างสม่ำเสมอ |
| Cost | มี open-source version ให้ใช้งานฟรี | enterprise features อาจต้องเสียค่าใช้จ่ายเพิ่ม |
| Scalability | รองรับ horizontal scaling ได้ | ต้องวางแผน capacity planning ล่วงหน้า |
สิ่งที่ต้องพิจารณาเพิ่มเติมเมื่อเลือกใช้ stable diffusion ui:
- Team skill set: เลือกเทคโนโลยีที่ทีมมีความคุ้นเคยหรือสามารถเรียนรู้ได้ในเวลาที่เหมาะสมอย่าเลือกเทคโนโลยีที่ดีที่สุดแต่ไม่มีใครใช้เป็น
- Ecosystem: ตรวจสอบว่ามี plugin, extension หรือ integration กับเครื่องมืออื่นที่ใช้อยู่หรือไม่เพื่อลดงาน integration
- Community support: เลือกเทคโนโลยีที่มี community ที่ active เพราะจะได้รับ support และอัปเดตอย่างต่อเนื่องมี Stack Overflow answers เยอะ
- Long-term viability: พิจารณาว่าเทคโนโลยีนี้จะยังคงได้รับการพัฒนาและ support ต่อไปในระยะยาวหรือไม่ดู GitHub stars, commit frequency, backing company
การนำความรู้ไปประยุกต์ใช้งานจริง
แหล่งเรียนรู้ที่แนะนำ ได้แก่ Official Documentation ที่อัพเดทล่าสุดเสมอ Online Course จาก Coursera Udemy edX ช่อง YouTube คุณภาพทั้งไทยและอังกฤษ และ Community อย่าง Discord Reddit Stack Overflow ที่ช่วยแลกเปลี่ยนประสบการณ์กับนักพัฒนาทั่วโลก
เปรียบเทียบข้อดีและข้อเสีย
จากตารางเปรียบเทียบจะเห็นว่าข้อดีมีมากกว่าข้อเสียอย่างชัดเจน โดยเฉพาะในแง่ของประสิทธิภาพและความสามารถในการ Scale สำหรับข้อเสียส่วนใหญ่สามารถแก้ไขได้ด้วยการเรียนรู้อย่างเป็นระบบและวางแผนทรัพยากรให้เหมาะสม
stable diffusion ui เหมาะกับงานประเภทไหน
เหมาะกับ web application, API development, microservices และ data processing สามารถประยุกต์ใช้ได้หลากหลาย
ควรใช้ stable diffusion ui คู่กับเครื่องมืออะไร
แนะนำใช้คู่กับ Git, CI/CD pipeline, testing framework และ monitoring tools เพื่อ workflow ที่สมบูรณ์
stable diffusion ui มี performance ดีแค่ไหน
performance ขึ้นอยู่กับการเขียนโค้ดและ architecture การ profiling และ optimization เป็นสิ่งสำคัญที่ต้องทำเป็นประจำ
เนื้อหาเกี่ยวข้อง — บทความที่เกี่ยวข้อง: Multus CNI Learning Path Roadmap
สรุป stable diffusion ui
stable diffusion ui เป็นเทคโนโลยีที่มีบทบาทสำคัญในการพัฒนาและดูแลระบบ IT สมัยใหม่จากที่ได้อธิบายมาทั้งหมดจะเห็นว่าการเข้าใจ stable diffusion ui อย่างถ่องแท้นั้นช่วยให้สามารถออกแบบระบบที่มีประสิทธิภาพปลอดภัยและ scale ได้
สรุปประเด็นสำคัญ:
- เข้าใจพื้นฐาน: stable diffusion ui ไม่ใช่แค่เครื่องมือเดียวแต่เป็นชุดของแนวคิดและ practices ที่ทำงานร่วมกัน
- ลงมือปฏิบัติ: ทฤษฎีอย่างเดียวไม่พอต้องลงมือทำจริงเริ่มจาก lab environment แล้วค่อยขยายไป production
- เรียนรู้ต่อเนื่อง: เทคโนโลยีเปลี่ยนแปลงตลอดเวลาต้อง update ความรู้อยู่เสมอติดตาม official blog, release notes และ community discussions
- แบ่งปันความรู้: การสอนผู้อื่นเป็นวิธีที่ดีที่สุดในการเรียนรู้เขียน blog, ทำ presentation หรือ contribute กลับให้ community
หากมีคำถามเพิ่มเติมสามารถติดตามบทความอื่นๆได้ที่ SiamCafe.net ซึ่งมีบทความ IT คุณภาพสูงภาษาไทยอัปเดตสม่ำเสมอเขียนโดยอ. บอมผู้เชี่ยวชาญด้าน IT Infrastructure, Network และ Cybersecurity
อ่านเพิ่มเติม: สอนเทรด Forex | XM Signal | IT Hardware | อาชีพ IT | SiamCafe Book | iCafe Cloud





