CrewAI Multi-Agent Best Practices ที่ต้องรู้
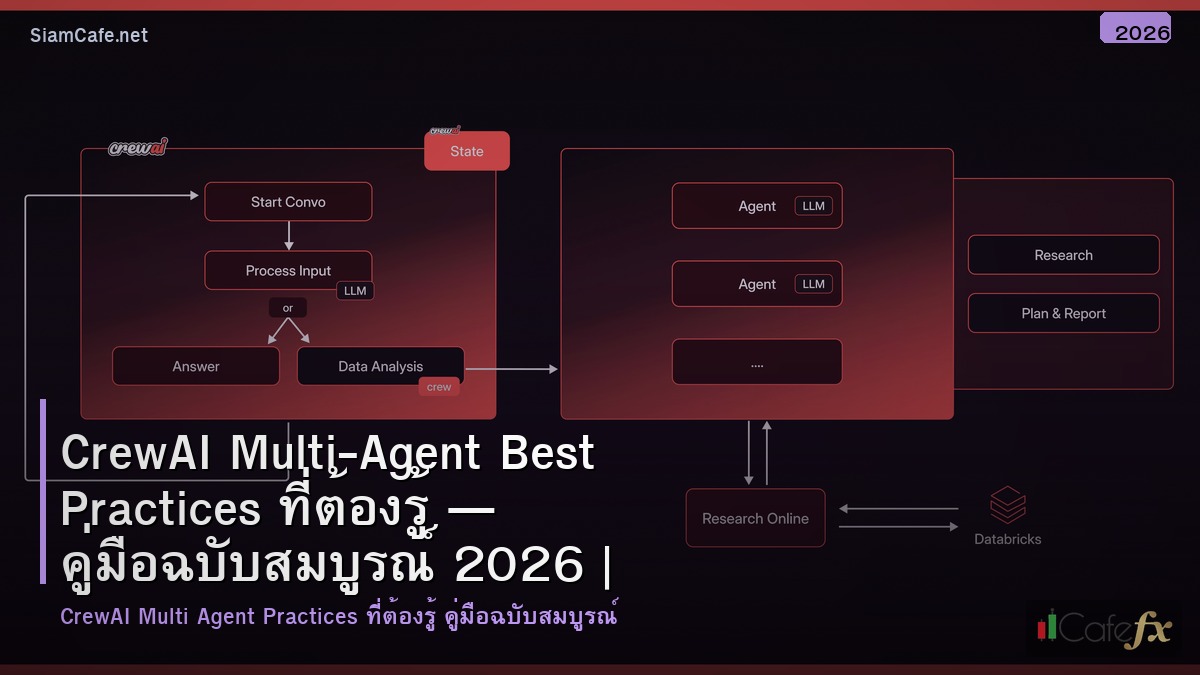

CrewAI Multi-Agent Best Practices ที่ต้องรู้ คืออะไร — ทำความเข้าใจพื้นฐาน

CrewAI Multi-Agent Best Practices ที่ต้องรู้ เป็นแนวทางที่ผสมผสานความรู้ด้าน Crewai Multi Agent Best Practices ทตองร เข้ากับหลักปฏิบัติจริงในระบบ production เพื่อสร้างระบบที่มีเสถียรภาพ รองรับการขยายตัวได้ดี และดูแลรักษาง่ายในระยะยาว
แนวคิดหลักคือการนำเครื่องมือและเทคนิคที่ผ่านการพิสูจน์แล้วมาประยุกต์ใช้กับโครงสร้างพื้นฐานขององค์กร โดยเน้นที่ automation, monitoring และ recovery เป็นหลัก
ในสภาพแวดล้อมจริงการนำ CrewAI Multi-Agent Best Practices ที่ต้องรู้ ไปใช้ต้องคำนึงถึงหลายปัจจัย ทั้งขนาดของระบบ จำนวนผู้ใช้งานพร้อมกัน ปริมาณข้อมูล และข้อจำกัดด้านทรัพยากร ซึ่งแต่ละองค์กรมีความต้องการแตกต่างกัน
Crewai Multi Agent Best Practices ทตองร ถูกพัฒนาขึ้นเพื่อตอบโจทย์เหล่านี้โดยเฉพาะ ด้วยสถาปัตยกรรมที่ออกแบบมาให้ยืดหยุ่นและขยายตัวได้ตามความต้องการโดยไม่ต้องเปลี่ยนแปลงโครงสร้างหลักของระบบ
ทำไม CrewAI Multi-Agent Best Practices ที่ต้องรู้ ถึงสำคัญ — สถาปัตยกรรมและหลักการทำงาน
ความสำคัญของ CrewAI Multi-Agent Best Practices ที่ต้องรู้ อยู่ที่การแก้ปัญหาที่องค์กรเผชิญอยู่ทุกวัน ไม่ว่าจะเป็นเรื่องของ system downtime, การ scale ระบบ, ความปลอดภัย หรือการจัดการ configuration ที่ซับซ้อน ทั้งหมดนี้ Crewai Multi Agent Best Practices ทตองร มีเครื่องมือและแนวทางที่ช่วยจัดการได้อย่างเป็นระบบ
สถาปัตยกรรมของ CrewAI Multi-Agent Best Practices ที่ต้องรู้ ประกอบด้วยส่วนหลักๆดังนี้:
เนื้อหาเกี่ยวข้อง — ดูเพิ่มเติมเรื่อง Kotlin Ktor Feature Flag Management
- Control Plane — ส่วนที่ควบคุมและจัดการ configuration ทั้งหมดของระบบ รับผิดชอบการตัดสินใจว่า request แต่ละตัวควรถูกส่งไปที่ไหนและจัดการอย่างไร
- Data Plane — ส่วนที่จัดการ traffic จริง ประมวลผลข้อมูลและส่งต่อระหว่าง service ต่างๆในระบบ
- Observability Layer — ระบบ monitoring ที่เก็บ metrics, logs และ traces สำหรับวิเคราะห์ performance และตรวจจับปัญหา
- Security Layer — จัดการ authentication, authorization และ encryption ระหว่าง service
การทำงานร่วมกันของส่วนประกอบเหล่านี้ทำให้ CrewAI Multi-Agent Best Practices ที่ต้องรู้ สามารถจัดการระบบที่มีความซับซ้อนสูงได้อย่างมีประสิทธิภาพ โดยผู้ดูแลระบบไม่ต้องเข้าไปแก้ไขทีละจุดแต่สามารถกำหนดนโยบายจากส่วนกลางและให้ระบบทำงานตามอัตโนมัติ
ข้อดีหลักของสถาปัตยกรรมนี้คือความสามารถในการ scale แบบ horizontal ได้โดยไม่ต้องเปลี่ยนแปลง code เพียงเพิ่ม node เข้าไปในระบบก็สามารถรองรับ load ที่เพิ่มขึ้นได้ทันที
แนะนำเพิ่มเติม — ระบบเทรดของ iCafeForex
การติดตั้งและตั้งค่า CrewAI Multi-Agent Best Practices ที่ต้องรู้ — ขั้นตอนจริง
การเริ่มต้นใช้งาน CrewAI Multi-Agent Best Practices ที่ต้องรู้ ต้องเตรียมสภาพแวดล้อมให้พร้อมก่อน ซึ่งรวมถึงการติดตั้ง dependencies ที่จำเป็น การตั้งค่า configuration และการทดสอบว่าระบบทำงานได้ถูกต้อง
ขั้นตอนการติดตั้งที่แนะนำมีดังนี้:
- ตรวจสอบ system requirements — CPU อย่างน้อย 2 cores, RAM 4GB ขึ้นไป, disk space 20GB
- ติดตั้ง dependencies ที่จำเป็น — Docker, Docker Compose, Python 3.8+
- Clone repository หรือสร้าง configuration files
- รัน initial setup และทดสอบ
ตัวอย่าง configuration สำหรับ CrewAI Multi-Agent Best Practices ที่ต้องรู้ ที่ใช้งานจริง:
เนื้อหาเกี่ยวข้อง — บทความที่เกี่ยวข้อง: LlamaIndex RAG Remote Work Setup
Crewai Multi Agent Best Practices ทตองร Setup Script
configuration ข้างต้นเป็นตัวอย่างที่สามารถนำไปปรับใช้ได้ทันที โดยค่าที่ต้องเปลี่ยนคือ credentials และ endpoint ต่างๆให้ตรงกับระบบของคุณ ควรเก็บ sensitive data ใน environment variables หรือ secret manager แทนการ hardcode ไว้ใน config file
หลังจากตั้งค่าเสร็จแล้ว สามารถรันคำสั่ง docker compose up -d เพื่อเริ่มต้นระบบ จากนั้นตรวจสอบสถานะด้วย docker compose ps ว่า service ทั้งหมดขึ้นมาอย่างถูกต้อง
การใช้งาน CrewAI Multi-Agent Best Practices ที่ต้องรู้ ขั้นสูง — เทคนิคและ Best Practices
เมื่อตั้งค่าพื้นฐานเรียบร้อยแล้ว ขั้นตอนถัดไปคือการนำ CrewAI Multi-Agent Best Practices ที่ต้องรู้ ไปใช้งานจริงอย่างเต็มประสิทธิภาพ ซึ่งต้องอาศัยความเข้าใจในด้าน performance tuning, error handling และ automation
Best practices ที่สำคัญสำหรับ CrewAI Multi-Agent Best Practices ที่ต้องรู้:
แนะนำเพิ่มเติม — หนังสือเทรดที่ SiamCafeBook
- ใช้ Infrastructure as Code (IaC) — กำหนด configuration ทั้งหมดเป็น code เก็บใน version control เพื่อให้สามารถ track changes, rollback และ reproduce environment ได้
- ตั้ง monitoring ตั้งแต่วันแรก — อย่ารอให้มีปัญหาแล้วค่อยตั้ง ให้เก็บ metrics, logs และ traces ตั้งแต่เริ่มต้น
- ทำ automated testing — ทั้ง unit tests, integration tests และ end-to-end tests เพื่อให้มั่นใจว่า configuration ใหม่ไม่ทำลายระบบเดิม
- วาง disaster recovery plan — เตรียมแผนสำรองสำหรับทุกสถานการณ์ที่อาจเกิดขึ้น ทดสอบ recovery process เป็นประจำ
- ใช้ GitOps workflow — ให้ Git repository เป็น single source of truth สำหรับ configuration ทั้งหมด
ตัวอย่าง code สำหรับการใช้งานขั้นสูง:
เนื้อหาเกี่ยวข้อง — บทความที่เกี่ยวข้อง: Prometheus Alertmanager DevSecOps Integration
Crewai Multi Agent Best Practices ทตองร Automation Script
code ข้างต้นแสดงถึงแนวทางการเขียนระบบที่ production-ready โดยมีการจัดการ error อย่างครบถ้วน มี logging สำหรับ debugging และมีโครงสร้างที่ขยายต่อได้ง่าย ให้สังเกตว่ามีการแยก concerns ออกจากกันอย่างชัดเจน ทำให้แต่ละส่วนสามารถ test และปรับปรุงได้อิสระ
การ Monitor และ Troubleshoot CrewAI Multi-Agent Best Practices ที่ต้องรู้

การ monitoring เป็นหัวใจสำคัญของการดูแลระบบ CrewAI Multi-Agent Best Practices ที่ต้องรู้ ให้ทำงานได้อย่างราบรื่น คุณต้องมี visibility ในทุกส่วนของระบบเพื่อตรวจจับและแก้ไขปัญหาได้อย่างรวดเร็ว
Metrics หลักที่ต้อง monitor สำหรับ CrewAI Multi-Agent Best Practices ที่ต้องรู้:
- Latency (P50, P95, P99) — วัดเวลาตอบสนองของระบบ ค่าที่ดีคือ P99 ไม่เกิน 200ms สำหรับ API calls ทั่วไป
- Error Rate — อัตราส่วน request ที่ล้มเหลว ค่าที่ยอมรับได้ควรต่ำกว่า 0.1% สำหรับ production
- Throughput — จำนวน request ต่อวินาทีที่ระบบรองรับได้ ควร monitor เทียบกับ capacity ที่วางไว้
- Resource Utilization — CPU, memory, disk I/O ของแต่ละ service
- Queue Depth — จำนวนงานที่รอ process อยู่ใน queue ถ้าเพิ่มขึ้นเรื่อยๆแสดงว่า consumers ประมวลผลไม่ทัน
Crewai Multi Agent Best Practices ทตองร Docker Compose
version: "3.8"
services:
crewai-multi-agent-best-practices-ทตองร-server:
image: crewai-multi-agent-best-practices-ทตองร/crewai-multi-agent-best-practices-ทตองร:latest
ports:
- "8080:8080"
environment:
- DATABASE_URL=postgresql://admin:secret@db:5432/crewai-multi-agent-best-practices-ทตองร_db
- REDIS_URL=redis://redis:6379/0
- LOG_LEVEL=info
volumes:
- ./crewai-multi-agent-best-practices-ทตองร-data:/app/data
depends_on:
- db
- redis
restart: unless-stopped
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/health"]
interval: 30s
timeout: 10s
retries: 3
db:
image: postgres:16-alpine
environment:
POSTGRES_DB: crewai-multi-agent-best-practices-ทตองร_db
POSTGRES_USER: admin
POSTGRES_PASSWORD: secret
volumes:
- pgdata:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U admin"]
interval: 10s
redis:
image: redis:7-alpine
command: redis-server --maxmemory 256mb --maxmemory-policy allkeys-lru
volumes:
pgdata:เมื่อเกิดปัญหาในระบบ CrewAI Multi-Agent Best Practices ที่ต้องรู้ ให้ทำตามขั้นตอน troubleshooting นี้:
- ตรวจสอบ logs — ดู error logs ล่าสุดเพื่อหาสาเหตุ ใช้คำสั่ง
docker compose logs --tail=100 -f - ตรวจสอบ resource usage — ดูว่า CPU, memory หรือ disk เต็มหรือไม่ ใช้
htopและdf -h - ตรวจสอบ network connectivity — ทดสอบว่า service ต่างๆสื่อสารกันได้ ใช้
curlหรือtelnet - ตรวจสอบ configuration — ดูว่า config ล่าสุดที่ deploy ไปมีปัญหาหรือไม่ เทียบกับ version ก่อนหน้า
- Rollback ถ้าจำเป็น — ถ้าระบุสาเหตุไม่ได้ภายใน 15 นาที ให้ rollback ไปใช้ version ก่อนหน้าก่อน แล้วค่อยแก้ไขทีหลัง
1. CrewAI Multi-Agent Best Practices ที่ต้องรู้ เหมาะกับโปรเจกต์ขนาดไหน?
CrewAI Multi-Agent Best Practices ที่ต้องรู้ สามารถใช้ได้ตั้งแต่โปรเจกต์ขนาดเล็กไปจนถึงระดับ enterprise ขนาดใหญ่ สำหรับทีมเล็กๆสามารถเริ่มจาก configuration พื้นฐานก่อนแล้วค่อยขยายเมื่อระบบเติบโต ข้อดีคือสถาปัตยกรรมถูกออกแบบมาให้ scale ได้โดยไม่ต้องเปลี่ยนแปลงโครงสร้างหลัก
เนื้อหาเกี่ยวข้อง — บทความที่เกี่ยวข้อง: Elasticsearch OpenSearch Security Hardening
2. ต้องมีความรู้พื้นฐานอะไรบ้างก่อนเริ่มใช้ CrewAI Multi-Agent Best Practices ที่ต้องรู้?
ควรมีความรู้พื้นฐานด้าน Linux command line, Docker, และแนวคิด networking เบื้องต้น สำหรับการใช้งานขั้นสูงควรเข้าใจ CI/CD pipeline, Infrastructure as Code และ monitoring concepts ด้วย แนะนำให้ศึกษาจาก documentation อย่างเป็นทางการก่อนเริ่มลงมือทำ
3. CrewAI Multi-Agent Best Practices ที่ต้องรู้ ต่างจากเครื่องมืออื่นในกลุ่มเดียวกันอย่างไร?
Crewai Multi Agent Best Practices ทตองร มีจุดเด่นที่ความยืดหยุ่นในการปรับแต่ง community ที่แข็งแกร่ง และ ecosystem ของ plugins/extensions ที่หลากหลาย เมื่อเทียบกับทางเลือกอื่นๆ Crewai Multi Agent Best Practices ทตองร มักได้คะแนนสูงในด้าน ease of use และ documentation ที่ครบถ้วน ทำให้เหมาะกับทีมที่ต้องการเริ่มใช้งานได้เร็ว
4. การ deploy CrewAI Multi-Agent Best Practices ที่ต้องรู้ ใน production มีข้อควรระวังอะไร?
ข้อควรระวังหลักๆคือต้องทดสอบใน staging environment ก่อน deploy ไป production เสมอ ตั้ง resource limits ให้เหมาะสม มี backup plan กรณีที่ต้อง rollback เปิด monitoring ตั้งแต่วันแรก และอย่าลืมตั้ง alerting สำหรับ critical metrics เพื่อให้สามารถตอบสนองต่อปัญหาได้ทันเวลา
5. มี community ภาษาไทยสำหรับ CrewAI Multi-Agent Best Practices ที่ต้องรู้ ไหม?
มี community คนไทยที่สนใจ Crewai Multi Agent Best Practices ทตองร อยู่หลายกลุ่ม ทั้งบน Facebook Groups, Discord servers และ LINE OpenChat สามารถแลกเปลี่ยนความรู้ ถามคำถาม และแชร์ประสบการณ์กับผู้ใช้งานคนอื่นได้ นอกจากนี้ SiamCafe.net ยังมีบทความเทคนิคภาษาไทยที่อัปเดตอย่างสม่ำเสมออีกด้วย





