Ceph Storage Cluster Cost Optimization

Ceph Cost Optimization
Ceph Storage Cluster Cost Optimization Erasure Coding Replication Tiering Compression HDD SSD NVMe CRUSH OSD RBD RGW CephFS Kubernetes OpenStack
| Storage Type | Overhead | Performance | Cost/TB | เหมาะกับ |
|---|---|---|---|---|
| 3x Replication | 3x | สูง | สูง | Hot Data, DB |
| EC k=4 m=2 | 1.5x | ปานกลาง | ต่ำ | Object Storage |
| EC k=8 m=3 | 1.375x | ต่ำกว่า | ต่ำมาก | Archive, Backup |
| 2x Replication | 2x | สูง | ปานกลาง | Non-critical |
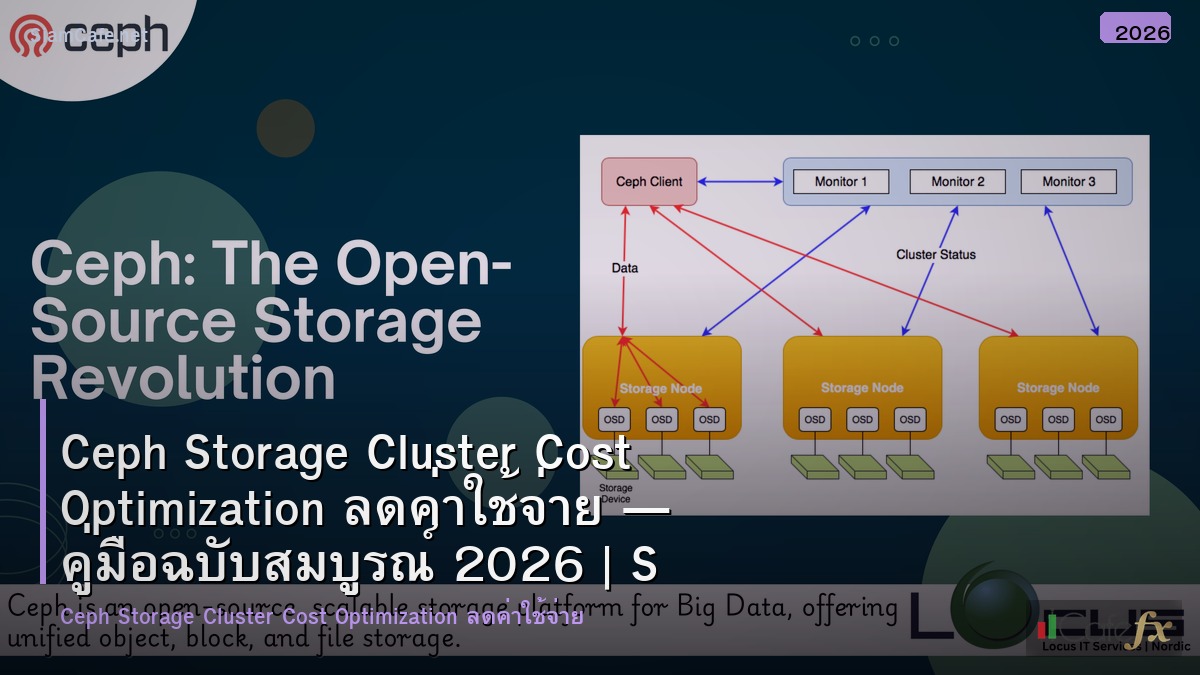
Cluster Design
=== Ceph Cluster Design ===
Hardware Recommendations
OSD Nodes (Storage):
CPU: 2x Intel Xeon 16-core
RAM: 128GB (16GB per OSD recommended)
HDD: 12x 16TB SATA (for capacity)
SSD: 2x 1TB NVMe (for WAL+DB)
Network: 2x 25GbE (public + cluster)
Monitor Nodes:
CPU: 8-core
RAM: 32GB
SSD: 500GB NVMe
Network: 10GbE
Count: 3 or 5 (odd number)
Manager Nodes (co-located with MON):
Dashboard, Prometheus, Grafana
ceph.conf
[global]
fsid = a1b2c3d4-e5f6-7890-abcd-ef1234567890
mon_initial_members = mon1, mon2, mon3
mon_host = 10.0.0.1, 10.0.0.2, 10.0.0.3
เนื้อหาเกี่ยวข้อง — อ่านต่อ: SASE Security Code Review Best Practice
public_network = 10.0.0.0/24
cluster_network = 10.0.1.0/24
[osd]
osd_memory_target = 4294967296 # 4GB per OSD
bluestore_cache_size = 3221225472 # 3GB
osd_max_backfills = 2
แนะนำเพิ่มเติม — อีบุ๊กการลงทุน SiamCafeBook
osd_recovery_max_active = 2
from dataclasses import dataclass
@dataclass
class ClusterNode:
role: str
count: int
cpu_cores: int
ram_gb: int
storage: str
network: str
cost_per_node: float
nodes = [
ClusterNode("OSD (HDD)", 6, 32, 128, "12x 16TB HDD + 2x 1TB NVMe", "2x 25GbE", 8000),
เนื้อหาเกี่ยวข้อง — ทำความเข้าใจ textile pattern design pdf — คู่มือฉบับสมบูรณ์ 2026
ClusterNode("OSD (SSD)", 3, 16, 64, "8x 4TB NVMe", "2x 25GbE", 12000),
ClusterNode("MON/MGR", 3, 8, 32, "500GB NVMe", "10GbE", 2000),
ClusterNode("RGW (S3)", 2, 8, 32, "500GB NVMe", "25GbE", 2500),
]
total_cost = 0
cost = n.cost_per_node * n.count
total_cost += cost
แนะนำเพิ่มเติม — iCafeForex
Erasure Coding และ Compression
=== Erasure Coding & Compression ===
Create EC Pool
ceph osd erasure-code-profile set ec-4-2 \
k=4 m=2 \crush-failure-domain=host
ceph osd pool create ec-data 128 erasure ec-4-2
ceph osd pool set ec-data allow_ec_overwrites true
เนื้อหาเกี่ยวข้อง — ดูเพิ่มเติมเรื่อง Kustomize Overlay Remote Work Setup
# Enable Compression
ceph osd pool set ec-data compression_algorithm zstd
ceph osd pool set ec-data compression_mode aggressive
ceph osd pool set ec-data compression_required_ratio 0.875
# Create Replicated Pool (for hot data)
ceph osd pool create hot-data 64 replicated
ceph osd pool set hot-data size 3 min_size 2
# CRUSH Rules — Separate SSD and HDD
ceph osd crush rule create-replicated ssd-rule default host ssd
ceph osd crush rule create-replicated hdd-rule default host hdd
ceph osd pool set hot-data crush_rule ssd-rule
ceph osd pool set ec-data crush_rule hdd-rule
@dataclass
class StorageSaving:

strategy: str
raw_tb: float
usable_tb: float
savings_pct: float
monthly_cost: float
เนื้อหาเกี่ยวข้อง — บทความที่เกี่ยวข้อง: EVPN Fabric CQRS Event Sourcing
Example: 100TB raw data
savings = [
StorageSaving("3x Replication (baseline)", 300, 100, 0, 3000),
StorageSaving("2x Replication", 200, 100, 33, 2000),
StorageSaving("EC k=4 m=2", 150, 100, 50, 1500),
StorageSaving("EC k=4 m=2 + Compression", 105, 100, 65, 1050),
StorageSaving("EC k=8 m=3 + Compression", 96, 100, 68, 960),
]
Monitoring และ Capacity
# === Monitoring & Capacity Planning ===
# Ceph Dashboard
# ceph mgr module enable dashboard
# ceph dashboard create-self-signed-cert
# ceph dashboard ac-user-create admin -i /tmp/password administrator
# Prometheus Integration
# ceph mgr module enable prometheus
# # Scrape endpoint: http://mgr-host:9283/metrics
# Key Metrics to Monitor
# - ceph_osd_utilization (target < 75%)
# - ceph_pool_stored_raw (actual data)
# - ceph_osd_apply_latency_ms (target < 10ms SSD, < 50ms HDD)
# - ceph_osd_commit_latency_ms
# - ceph_pg_degraded (should be 0)
# - ceph_health_status (HEALTH_OK)
# Capacity Planning
# ceph df detail
# ceph osd df tree
@dataclass
class PoolMetric:
pool: str
type: str
stored_tb: float
raw_tb: float
usage_pct: float
iops: int
latency_ms: float
pools = [
PoolMetric("kubernetes-rbd", "3x Replica", 8.5, 25.5, 72, 15000, 2.5),
PoolMetric("object-storage", "EC 4+2", 45.0, 67.5, 58, 3000, 8.0),
PoolMetric("backup-archive", "EC 8+3", 120.0, 165.0, 65, 500, 25.0),
PoolMetric("cephfs-data", "3x Replica", 5.0, 15.0, 45, 8000, 3.0),
PoolMetric("vm-images", "2x Replica", 12.0, 24.0, 60, 5000, 5.0),
]
print("Pool Dashboard:")
total_stored = 0
total_raw = 0
for p in pools:
total_stored += p.stored_tb
total_raw += p.raw_tb
print(f" [{p.pool}] {p.type}")
print(f" Stored: {p.stored_tb}TB | Raw: {p.raw_tb}TB | Usage: {p.usage_pct}%")
print(f" IOPS: {p.iops:,} | Latency: {p.latency_ms}ms")
print(f"\n Total Stored: {total_stored:.1f}TB | Total Raw: {total_raw:.1f}TB")
print(f" Effective Ratio: {total_raw/total_stored:.2f}x")
# Cost Optimization Checklist
checklist = [
"EC สำหรับ Object Storage และ Archive ลด 50%+",
"Compression zstd สำหรับ Text/Log Data ลด 30-50%",
"CRUSH Tiering: SSD Hot / HDD Cold",
"PG Autoscaler เปิด ไม่ต้อง Manual",
"OSD Memory Target ปรับตาม RAM ที่มี",
"Network แยก Public/Cluster ลด Congestion",
"Capacity Alert ตั้งที่ 75% วางแผนซื้อล่วงหน้า",
]
print(f"\n\nOptimization Checklist:")
for i, c in enumerate(checklist, 1):
print(f" {i}. {c}")เคล็ดลับ
- EC: ใช้ Erasure Coding สำหรับ Cold Data ประหยัด 50%+
- Compression: เปิด zstd Compression ลดอีก 30%
- Tiering: SSD สำหรับ Hot Data HDD สำหรับ Cold Data
- Monitor: ดู OSD Utilization ไม่เกิน 75%
- Network: แยก Public/Cluster Network ใช้ 25GbE
การนำความรู้ไปประยุกต์ใช้งานจริง
แหล่งเรียนรู้ที่แนะนำ ได้แก่ Official Documentation ที่อัพเดทล่าสุดเสมอ Online Course จาก Coursera Udemy edX ช่อง YouTube คุณภาพทั้งไทยและอังกฤษ และ Community อย่าง Discord Reddit Stack Overflow ที่ช่วยแลกเปลี่ยนประสบการณ์กับนักพัฒนาทั่วโลก
Ceph Storage คืออะไร
Open Source SDS Block Object File OSD CRUSH Replication Erasure Coding Self-healing Scale-out Kubernetes OpenStack VMware
ลดค่าใช้จ่าย Ceph ได้อย่างไร
Erasure Coding 50% HDD Cold SSD Hot Compression zstd 30% Tiering Capacity Planning JBOD PG Count ปรับ
Erasure Coding กับ Replication ต่างกันอย่างไร
Replication 3x Storage 3 เท่า เร็ว Recovery เร็ว EC k=4 m=2 Storage 1.5 เท่า ประหยัด ช้ากว่า Cold Archive
Ceph Hardware เลือกอย่างไร
OSD HDD 16TB NVMe WAL DB RAM 16-64GB CPU 8-16 25GbE MON 32GB SSD 3-5 Node JBOD ไม่ RAID แยก Network
สรุป
Ceph Storage Cluster Cost Optimization Erasure Coding Compression zstd Tiering SSD HDD CRUSH OSD Replication Capacity Planning Monitoring Kubernetes Production





