LLM Inference คืออะไร? vLLM และ MLOps Workflow ขับเคลื่อน AI อย่างไร

LLM Inference คืออะไร?
LLM Inference คือกระบวนการที่โมเดลภาษาขนาดใหญ่ (Large Language Model - LLM) ทำการประมวลผลข้อมูลที่ได้รับเพื่อให้ได้ผลลัพธ์ เช่น การสร้างคำตอบ การทำนายข้อความ หรือการให้คำแนะนำ โดยใช้ความรู้และรูปแบบที่เรียนรู้มาจากข้อมูลจำนวนมาก
ความสำคัญของ LLM Inference
- ประสิทธิภาพ: LLM Inference ถูกออกแบบมาเพื่อให้มีประสิทธิภาพสูง สามารถประมวลผลข้อมูลได้รวดเร็วและแม่นยำ
- การปรับแต่ง: สามารถปรับแต่ง LLM Inference ให้เหมาะกับความต้องการเฉพาะของแต่ละองค์กรได้
- ความยืดหยุ่น: รองรับการใช้งานที่หลากหลาย เช่น การสนทนาผ่านแชทบอท การสร้างเนื้อหา และการวิเคราะห์ข้อมูล
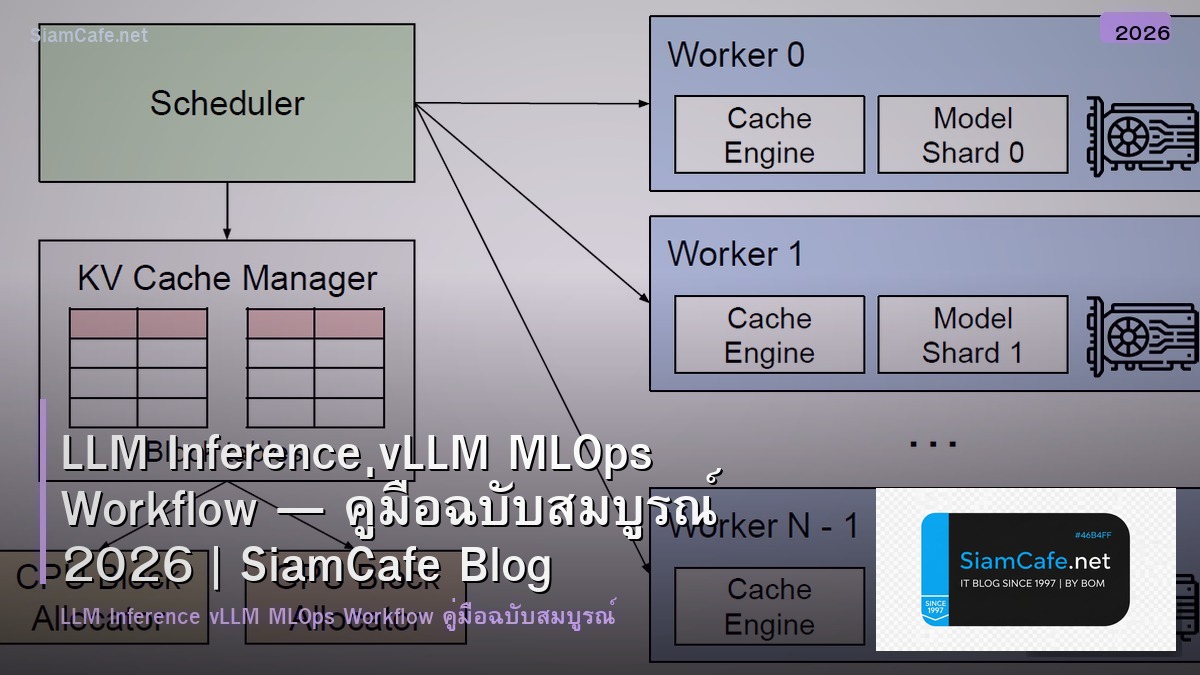
vLLM คืออะไร?
vLLM (Virtual Large Language Model) คือการใช้เทคโนโลยี Virtualization เพื่อให้บริการ LLM Inference ในรูปแบบที่สามารถเข้าถึงได้ง่ายและมีประสิทธิภาพสูง โดยไม่ต้องลงทุนในฮาร์ดแวร์ที่มีราคาสูง
เนื้อหาเกี่ยวข้อง — trade your way to financial freedom แปลไทย
ประโยชน์ของ vLLM
- ต้นทุนที่ต่ำกว่า: ลดต้นทุนในการลงทุนฮาร์ดแวร์และโครงสร้างพื้นฐาน
- ความยืดหยุ่น: สามารถขยายหรือลดขนาดทรัพยากรได้ตามความต้องการ
- การเข้าถึงที่ง่าย: สามารถเข้าถึง LLM Inference ได้ผ่านแพลตฟอร์มออนไลน์
MLOps Workflow คืออะไร?
MLOps (Machine Learning Operations) คือการผสมผสานระหว่าง Machine Learning และ DevOps เพื่อสร้างกระบวนการที่มีประสิทธิภาพในการพัฒนา ปรับปรุง และบำรุงรักษาโมเดล Machine Learning โดย MLOps Workflow คือลำดับขั้นตอนในการทำงานเหล่านี้
แนะนำเพิ่มเติม — ติดตาม XM Signal
เนื้อหาเกี่ยวข้อง — ทำความเข้าใจ DNS over HTTPS AR VR Development
ขั้นตอนหลักของ MLOps Workflow
- Data Collection and Preprocessing: การรวบรวมและเตรียมข้อมูลสำหรับการฝึกโมเดล
- Model Training and Evaluation: การฝึกโมเดลและการประเมินประสิทธิภาพของโมเดล
- Model Deployment: การนำโมเดลไปใช้งานจริง
- Monitoring and Maintenance: การตรวจสอบและบำรุงรักษาโมเดลหลังการนำไปใช้งาน
การนำ LLM Inference, vLLM และ MLOps Workflow มาใช้งานจริง
องค์กรต่างๆ สามารถนำ LLM Inference, vLLM และ MLOps Workflow มาใช้งานจริงเพื่อเพิ่มประสิทธิภาพและสร้างความได้เปรียบในการแข่งขัน เช่น:
แนะนำเพิ่มเติม — คู่มือเทรดจาก SiamCafeBook
เนื้อหาเกี่ยวข้อง — ทำความเข้าใจ Delta Lake SSL TLS Certificate —
- แชทบอท: ใช้ LLM Inference และ vLLM เพื่อสร้างแชทบอทที่สามารถตอบคำถามและให้คำแนะนำได้อย่างแม่นยำ
- การสร้างเนื้อหา: ใช้ LLM Inference เพื่อสร้างบทความ ข้อความ และเนื้อหาอื่นๆ อัตโนมัติ
- การวิเคราะห์ข้อมูล: ใช้ MLOps Workflow เพื่อวิเคราะห์ข้อมูลและทำนายแนวโน้มในอนาคต
สรุป
LLM Inference, vLLM และ MLOps Workflow เป็นเครื่องมือที่สำคัญในการขับเคลื่อน AI ให้มีประสิทธิภาพสูงสุด การเข้าใจและนำเครื่องมือเหล่านี้มาใช้งานอย่างเหมาะสมจะช่วยให้องค์กรสามารถสร้างความได้เปรียบในการแข่งขันและตอบสนองความต้องการของลูกค้าได้อย่างมีประสิทธิภาพ
เนื้อหาเกี่ยวข้อง — แนะนำให้อ่าน Elasticsearch OpenSearch Multi-tenant Design





