LLM Fine-tuning LoRA Infrastructure as Code

LLM Fine-tuning LoRA Infrastructure as Code คืออะไร — ทำความเข้าใจพื้นฐาน

LLM Fine-tuning LoRA Infrastructure as Code เป็นเทคโนโลยี data engineering ที่จัดการข้อมูลอย่างมีระบบ ตั้งแต่ ingestion, transformation ถึง analytics
ข้อดีหลักคือลดความซับซ้อนของ data pipeline ให้ทีมโฟกัส business logic และช่วยให้ข้อมูลมี quality ดีผ่านการ validate อย่างเป็นระบบ
LLM Fine-tuning LoRA Infrastructure as Code รองรับทั้ง batch และ stream processing ยืดหยุ่นต่อ use case หลากหลาย
องค์ประกอบสำคัญและสถาปัตยกรรม
เพื่อเข้าใจ LLM Fine-tuning LoRA Infrastructure as Code อย่างครบถ้วน ต้องเข้าใจองค์ประกอบหลักที่ทำงานร่วมกัน ด้านล่างเป็น configuration จริงที่ใช้ในสภาพแวดล้อม production
เนื้อหาเกี่ยวข้อง — บทความที่เกี่ยวข้อง: Monte Carlo Observability Batch Processing
apiVersion: apps/v1
kind: Deployment
metadata:
name: llm-fine-tuning-lora-infrastructure-as-c
namespace: production
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
selector:
matchLabels:
app: llm-fine-tuning-lora-infrastructure-as-c
template:
metadata:
labels:
app: llm-fine-tuning-lora-infrastructure-as-c
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9090"
spec:
containers:
- name: app
image: registry.example.com/llm-fine-tuning-lora-infrastructure-as-c:latest
ports:
- containerPort: 8080
- containerPort: 9090
resources:
requests:
cpu: "250m"
memory: "256Mi"
limits:
cpu: "1000m"
memory: "1Gi"
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
---
apiVersion: v1
kind: Service
metadata:
name: llm-fine-tuning-lora-infrastructure-as-c
spec:
type: ClusterIP
ports:
- port: 80
targetPort: 8080
selector:
app: llm-fine-tuning-lora-infrastructure-as-c
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: llm-fine-tuning-lora-infrastructure-as-c
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: llm-fine-tuning-lora-infrastructure-as-c
minReplicas: 3
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70การติดตั้งและเริ่มต้นใช้งาน
ขั้นตอนการติดตั้ง LLM Fine-tuning LoRA Infrastructure as Code เริ่มจากเตรียม environment จากนั้นติดตั้ง dependencies และตั้งค่า
#!/bin/bash
set -euo pipefail
echo "=== Install Dependencies ==="
sudo apt-get update && sudo apt-get install -y \
curl wget git jq apt-transport-https \
ca-certificates software-properties-common gnupg
if ! command -v docker &> /dev/null; then
curl -fsSL https://get.docker.com | sh
sudo usermod -aG docker $USER
sudo systemctl enable --now docker
fi
curl -LO "https://dl.k8s.io/release/$(curl -sL https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
echo "=== Verify ==="
docker --version && kubectl version --client && helm version --short
mkdir -p ~/projects/llm-fine-tuning-lora-infrastructure-as-c/{manifests, scripts, tests, monitoring}
cd ~/projects/llm-fine-tuning-lora-infrastructure-as-c
cat > Makefile <<'MAKEFILE'
.PHONY: deploy rollback status logs
deploy:
kubectl apply -k manifests/overlays/production/
kubectl rollout status deployment/llm-fine-tuning-lora-infrastructure-as-c -n production --timeout=300s
rollback:
kubectl rollout undo deployment/llm-fine-tuning-lora-infrastructure-as-c -n production
status:
kubectl get pods -l app=llm-fine-tuning-lora-infrastructure-as-c -n production -o wide
logs:
kubectl logs -f deployment/llm-fine-tuning-lora-infrastructure-as-c -n production --tail=100
MAKEFILE
echo "Setup complete"Monitoring และ Health Check
การ monitor LLM Fine-tuning LoRA Infrastructure as Code ต้องครอบคลุมทุกระดับ เพื่อตรวจจับปัญหาก่อนกระทบ user
แนะนำเพิ่มเติม — iCafeForex
ตารางเปรียบเทียบ

| Metric | คำอธิบาย | Threshold |
|---|---|---|
| Row Count | จำนวนแถวต่อ run | ไม่ลดเกิน 20% |
| Data Freshness | ความสดข้อมูล | ไม่เกิน 2x interval |
| Null Rate | % null fields | ไม่เกิน 1% |
| Duplicate Rate | % ซ้ำ | 0% หลัง dedup |
| Duration | เวลา pipeline | ไม่เกิน 2x avg |
Best Practices
- ใช้ GitOps Workflow — ทุกการเปลี่ยนแปลงผ่าน Git ห้ามแก้ production ด้วย kubectl edit
- ตั้ง Resource Limits ทุก Pod — ป้องกัน pod ใช้ resource กระทบตัวอื่น
- มี Rollback Strategy — ทดสอบ rollback เป็นประจำ ใช้ revision history
- แยก Config จาก Code — ใช้ ConfigMap/Secrets แยก config
- Network Policies — จำกัด traffic ระหว่าง pod เฉพาะที่จำเป็น
- Chaos Engineering — ทดสอบ pod/node failure เป็นประจำ
Best Practices สำหรับนักพัฒนา
การเขียนโค้ดที่ดีไม่ใช่แค่ทำให้โปรแกรมทำงานได้ แต่ต้องเขียนให้อ่านง่าย ดูแลรักษาง่าย และ Scale ได้ หลัก SOLID Principles เป็นพื้นฐานสำคัญที่นักพัฒนาทุกคนควรเข้าใจ ได้แก่ Single Responsibility ที่แต่ละ Class ทำหน้าที่เดียว Open-Closed ที่เปิดให้ขยายแต่ปิดการแก้ไข Liskov Substitution ที่ Subclass ต้องใช้แทน Parent ได้ Interface Segregation ที่แยก Interface ให้เล็ก และ Dependency Inversion ที่พึ่งพา Abstraction ไม่ใช่ Implementation
เรื่อง Testing ก็ขาดไม่ได้ ควรเขียน Unit Test ครอบคลุมอย่างน้อย 80% ของ Code Base ใช้ Integration Test ทดสอบการทำงานร่วมกันของ Module ต่างๆ และ E2E Test สำหรับ Critical User Flow เครื่องมือยอดนิยมเช่น Jest, Pytest, JUnit ช่วยให้การเขียน Test เป็นเรื่องง่าย
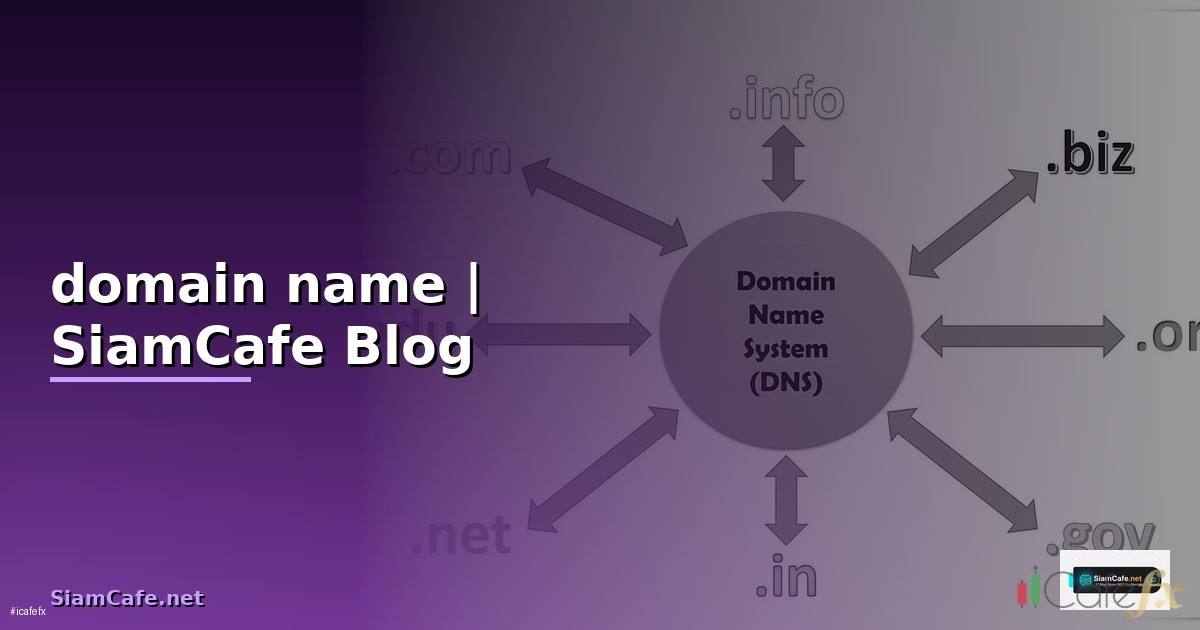
เนื้อหาเกี่ยวข้อง — แนะนำให้อ่าน domain name คืออะไรมีประโยชน์อย่างไร
เรื่อง Version Control ด้วย Git ใช้ Branch Strategy ที่เหมาะกับทีม เช่น Git Flow สำหรับโปรเจคใหญ่ หรือ Trunk-Based Development สำหรับทีมที่ Deploy บ่อย ทำ Code Review ทุก Pull Request และใช้ CI/CD Pipeline ทำ Automated Testing และ Deployment
เปรียบเทียบข้อดีและข้อเสีย
จากตารางเปรียบเทียบจะเห็นว่าข้อดีมีมากกว่าข้อเสียอย่างชัดเจน โดยเฉพาะในแง่ของประสิทธิภาพและความสามารถในการ Scale สำหรับข้อเสียส่วนใหญ่สามารถแก้ไขได้ด้วยการเรียนรู้อย่างเป็นระบบและวางแผนทรัพยากรให้เหมาะสม
คำถามที่พบบ่อย (FAQ)
Q: LLM Fine-tuning LoRA Infrastructure as Code ต่างจากเครื่องมืออื่นอย่างไร?
แนะนำเพิ่มเติม — XM Signal
A: จุดแข็งคือ flexibility รองรับ data source หลากหลาย community ใหญ่ เหมาะกับ pipeline ซับซ้อน
เนื้อหาเกี่ยวข้อง — อ่านต่อ: Prometheus Alertmanager Technical Debt Management
Q: รองรับข้อมูลขนาดใหญ่แค่ไหน?
A: ตั้งแต่หลักพันถึงหลายพันล้านแถว workload ใหญ่ใช้ Spark ร่วมด้วย
Q: ใช้ร่วมกับ real-time ได้ไหม?
A: ได้ทั้ง batch/real-time สำหรับ streaming ใช้ Kafka หรือ Pulsar ร่วมด้วย
เนื้อหาเกี่ยวข้อง — Elasticsearch Aggregation Machine Learning
Q: ต้องรู้ภาษาอะไร?
A: SQL เป็นพื้นฐาน Python สำหรับ pipeline code และ YAML สำหรับ config