Data Structures และ Algorithms คืออะไร? พื้นฐานที่ Developer ทุกคนต้องรู้ สำหรับสัมภาษณ์งาน 2026

Data Structures และ Algorithms (DSA) เป็นหัวใจของวิทยาการคอมพิวเตอร์และพื้นฐานที่ Developer ทุกคนต้องเข้าใจ ไม่ว่าคุณจะเขียน Web App, Mobile App, หรือ AI System ล้วนต้องใช้ Data Structures ในการจัดเก็บข้อมูลและ Algorithms ในการประมวลผล การเลือก Data Structure ที่ถูกต้องอาจทำให้โปรแกรมทำงานเร็วขึ้นเป็นร้อยเป็นพันเท่า ในขณะที่การเลือกผิดอาจทำให้ระบบล่มเมื่อข้อมูลมากขึ้น
ในปี 2026 บริษัท Tech ชั้นนำทั่วโลก ไม่ว่าจะเป็น Google, Meta, Amazon, LINE หรือ Agoda ล้วนใช้ DSA เป็นเกณฑ์หลักในการสัมภาษณ์งาน Developer บทความนี้จะสอนตั้งแต่พื้นฐาน Big O Notation โครงสร้างข้อมูลทุกประเภท Algorithm ที่ใช้บ่อยที่สุด พร้อมตัวอย่างโค้ด Python และกลยุทธ์เตรียมตัวสัมภาษณ์งาน
อ่านเพิ่ม: Concurrency และ Parallelism คืออะไร? สอนเขียนโปรแกรมแบบ Asyn · อ่านเพิ่ม: Rate Limiting คืออะไร? สอนป้องกัน API ด้วย Rate Limit, Throt · อ่านเพิ่ม: Caching Strategy และ CDN คืออะไร? สอนออกแบบ Cache Layer สำหร
ทำไม DSA ถึงสำคัญ?

หลายคนอาจคิดว่า DSA เป็นเรื่องทฤษฎีที่ไม่ได้ใช้ในงานจริง แต่ความจริงแล้วคุณใช้มันทุกวันโดยไม่รู้ตัว ทุกครั้งที่คุณใช้ dict ใน Python คุณกำลังใช้ Hash Table ทุกครั้งที่คุณกด Back ในเบราว์เซอร์ คุณกำลังใช้ Stack ทุกครั้งที่ Google แสดงผลค้นหาภายในเสี้ยววินาที เบื้องหลังคือ Algorithm ที่ซับซ้อน
- Performance: โปรแกรมที่ใช้ Data Structure ที่ถูกต้องจะเร็วขึ้นหลายร้อยเท่า เช่น การค้นหาใน Sorted Array ด้วย Binary Search ใช้เวลา O(log n) แทน O(n) ถ้าข้อมูลมี 1 ล้าน Record จาก 1,000,000 ขั้นตอนเหลือแค่ 20 ขั้นตอน
- Scalability: เมื่อข้อมูลเพิ่มจาก 1,000 เป็น 1,000,000 ถ้าใช้ Algorithm O(n^2) เวลาจะเพิ่มจาก 1 วินาทีเป็น 11.5 วัน แต่ถ้าใช้ O(n log n) จะเพิ่มแค่จาก 1 วินาทีเป็น 20 วินาที
- สัมภาษณ์งาน: บริษัท Tech เกือบทั้งหมดใช้โจทย์ DSA ในการสัมภาษณ์ เพราะมันวัดความสามารถในการคิดเชิงตรรกะและแก้ปัญหา ไม่ใช่แค่ท่องจำ API
- Foundation: ทุก Framework และ Library สร้างอยู่บน DSA การเข้าใจพื้นฐานจะทำให้เข้าใจเครื่องมือที่ใช้อย่างลึกซึ้ง และสามารถ Debug ปัญหา Performance ได้
Big O Notation — ภาษาของ Performance
Big O Notation คือวิธีอธิบายว่า Algorithm ทำงานช้าลงแค่ไหนเมื่อข้อมูลเพิ่มขึ้น ไม่ได้วัดเวลาเป็นวินาที แต่วัดเป็น "อัตราการเติบโต" ของจำนวนขั้นตอน เทียบกับขนาดข้อมูล (n)
| Big O | ชื่อ | ตัวอย่าง | n=1M ขั้นตอน |
|---|---|---|---|
| O(1) | Constant | เข้าถึง Array ด้วย Index | 1 |
| O(log n) | Logarithmic | Binary Search | 20 |
| O(n) | Linear | วนลูปทั้ง Array | 1,000,000 |
| O(n log n) | Log-linear | Merge Sort, Quick Sort | 20,000,000 |
| O(n^2) | Quadratic | Bubble Sort, Nested loops | 1,000,000,000,000 |
| O(2^n) | Exponential | Recursive Fibonacci (naive) | ไม่มีทางเสร็จ |
| O(n!) | Factorial | Brute-force Permutation | ไม่มีทางเสร็จ |
# O(1) - Constant Time
def get_first(arr):
return arr[0] # ไม่ว่า array จะยาวเท่าไหร่ ใช้ 1 ขั้นตอนเสมอ
# O(n) - Linear Time
def find_max(arr):
maximum = arr[0]
for num in arr: # วนทุกตัว — ข้อมูลเยอะ = ช้า
if num > maximum:
maximum = num
return maximum
# O(n^2) - Quadratic Time
def has_duplicate(arr):
for i in range(len(arr)):
for j in range(i + 1, len(arr)): # Nested loop = n * n
if arr[i] == arr[j]:
return True
return False
# O(n^2) ปรับเป็น O(n) ด้วย Hash Set
def has_duplicate_fast(arr):
seen = set()
for num in arr: # Loop เดียว
if num in seen: # set lookup = O(1)
return True
seen.add(num)
return FalseArrays และ Linked Lists
Arrays (รายการ)
Array เป็น Data Structure พื้นฐานที่สุดที่เก็บข้อมูลเรียงกันในหน่วยความจำ ทำให้เข้าถึงด้วย Index ได้ทันที (O(1)) แต่การเพิ่ม/ลบตรงกลางต้องเลื่อนข้อมูลทั้งหมด (O(n)) ใน Python ใช้ list ซึ่งเป็น Dynamic Array ที่ขยายขนาดได้อัตโนมัติ
เนื้อหาเกี่ยวข้อง — แนะนำให้อ่าน Python Pydantic Log Management ELK — คู่มือฉบับสมบูรณ์ 2026
# Array operations ใน Python
arr = [10, 20, 30, 40, 50]
# O(1) — Access by index
print(arr[2]) # 30
# O(1) — Append at end
arr.append(60) # [10, 20, 30, 40, 50, 60]
# O(n) — Insert at beginning (ต้องเลื่อนทุกตัว)
arr.insert(0, 5) # [5, 10, 20, 30, 40, 50, 60]
# O(n) — Search (Linear Search)
print(30 in arr) # True — ต้องดูทีละตัว
# O(1) — Pop from end
arr.pop() # ลบตัวสุดท้าย
# O(n) — Pop from beginning
arr.pop(0) # ลบตัวแรก — ต้องเลื่อนทุกตัวLinked Lists (รายการเชื่อมโยง)
Linked List เก็บข้อมูลเป็น Node ที่เชื่อมกันด้วย Pointer ไม่จำเป็นต้องอยู่ติดกันในหน่วยความจำ การเพิ่ม/ลบที่หัวหรือท้ายทำได้เร็ว (O(1)) แต่การเข้าถึงด้วย Index ต้องเดินไปทีละ Node (O(n))
class Node:
def __init__(self, data):
self.data = data
self.next = None
class LinkedList:
def __init__(self):
self.head = None
def prepend(self, data):
"""เพิ่มที่หัว — O(1)"""
new_node = Node(data)
new_node.next = self.head
self.head = new_node
def append(self, data):
"""เพิ่มที่ท้าย — O(n) สำหรับ Singly Linked List"""
new_node = Node(data)
if not self.head:
self.head = new_node
return
current = self.head
while current.next:
current = current.next
current.next = new_node
def delete(self, data):
"""ลบ Node ที่มีค่า data — O(n)"""
if not self.head:
return
if self.head.data == data:
self.head = self.head.next
return
current = self.head
while current.next and current.next.data != data:
current = current.next
if current.next:
current.next = current.next.next
def display(self):
elements = []
current = self.head
while current:
elements.append(str(current.data))
current = current.next
print(" -> ".join(elements))
# ใช้งาน
ll = LinkedList()
ll.append(10)
ll.append(20)
ll.append(30)
ll.prepend(5)
ll.display() # 5 -> 10 -> 20 -> 30
ll.delete(20)
ll.display() # 5 -> 10 -> 30| Operation | Array | Linked List |
|---|---|---|
| Access by Index | O(1) | O(n) |
| Insert at Beginning | O(n) | O(1) |
| Insert at End | O(1)* | O(n) / O(1)** |
| Delete | O(n) | O(n) |
| Search | O(n) | O(n) |
* Amortized, ** O(1) ถ้าเก็บ Tail pointer
Stacks และ Queues
Stack (กองซ้อน) — LIFO
Stack ทำงานแบบ Last In, First Out (LIFO) — ของที่ใส่เข้าไปทีหลังจะถูกหยิบออกก่อน เหมือนกองจาน จานที่วางไว้บนสุดจะถูกหยิบก่อน ใช้ใน Undo/Redo, Browser History, Function Call Stack และ Parentheses Matching
แนะนำเพิ่มเติม — ติดตาม XM Signal
class Stack:
def __init__(self):
self._items = []
def push(self, item):
self._items.append(item) # O(1)
def pop(self):
if self.is_empty():
raise IndexError("Stack is empty")
return self._items.pop() # O(1)
def peek(self):
if self.is_empty():
raise IndexError("Stack is empty")
return self._items[-1] # O(1)
def is_empty(self):
return len(self._items) == 0
def size(self):
return len(self._items)
# ตัวอย่าง: ตรวจสอบวงเล็บ
def is_balanced(expression: str) -> bool:
stack = Stack()
pairs = {'(': ')', '[': ']', '{': '}' }
for char in expression:
if char in pairs:
stack.push(char)
elif char in pairs.values():
if stack.is_empty():
return False
opening = stack.pop()
if pairs[opening] != char:
return False
return stack.is_empty()
print(is_balanced("(([]){})")) # True
print(is_balanced("([)]")) # False
print(is_balanced("((())")) # FalseQueue (แถวคอย) — FIFO
Queue ทำงานแบบ First In, First Out (FIFO) — ของที่เข้าคิวก่อนจะถูกจัดการก่อน เหมือนคิวซื้อตั๋วหนัง คนที่มาก่อนได้ก่อน ใช้ใน Task Queue, BFS, Printer Queue และ Message Queue
from collections import deque
class Queue:
def __init__(self):
self._items = deque()
def enqueue(self, item):
self._items.append(item) # O(1)
def dequeue(self):
if self.is_empty():
raise IndexError("Queue is empty")
return self._items.popleft() # O(1) — deque เร็วกว่า list.pop(0)
def peek(self):
if self.is_empty():
raise IndexError("Queue is empty")
return self._items[0]
def is_empty(self):
return len(self._items) == 0
# ตัวอย่าง: Task Processor
task_queue = Queue()
task_queue.enqueue("Send email to user A")
task_queue.enqueue("Generate report")
task_queue.enqueue("Backup database")
while not task_queue.is_empty():
task = task_queue.dequeue()
print(f"Processing: {task}")Hash Tables / Hash Maps
Hash Table (ใน Python คือ dict) เป็น Data Structure ที่ทรงพลังที่สุดตัวหนึ่ง ทำให้ค้นหา เพิ่ม และลบข้อมูลด้วย Key ได้ในเวลา O(1) โดยเฉลี่ย ทำงานโดยใช้ Hash Function แปลง Key เป็น Index ของ Array ภายใน
# Python dict คือ Hash Table
phonebook = {}
# Insert — O(1)
phonebook["Somchai"] = "081-234-5678"
phonebook["Somying"] = "082-345-6789"
phonebook["Somsak"] = "083-456-7890"
# Lookup — O(1)
print(phonebook["Somchai"]) # 081-234-5678
# Check existence — O(1)
print("Somying" in phonebook) # True
# Delete — O(1)
del phonebook["Somsak"]
# ตัวอย่าง: นับความถี่ของคำ
def word_frequency(text: str) -> dict:
freq = {}
for word in text.lower().split():
freq[word] = freq.get(word, 0) + 1
return freq
text = "the cat sat on the mat the cat"
print(word_frequency(text))
# {'the': 3, 'cat': 2, 'sat': 1, 'on': 1, 'mat': 1}
# ตัวอย่าง: Two Sum Problem (โจทย์สัมภาษณ์ยอดนิยม)
def two_sum(nums: list, target: int) -> list:
seen = {} # value -> index
for i, num in enumerate(nums):
complement = target - num
if complement in seen:
return [seen[complement], i]
seen[num] = i
return []
print(two_sum([2, 7, 11, 15], 9)) # [0, 1] — nums[0]+nums[1]=9Trees — โครงสร้างแบบต้นไม้
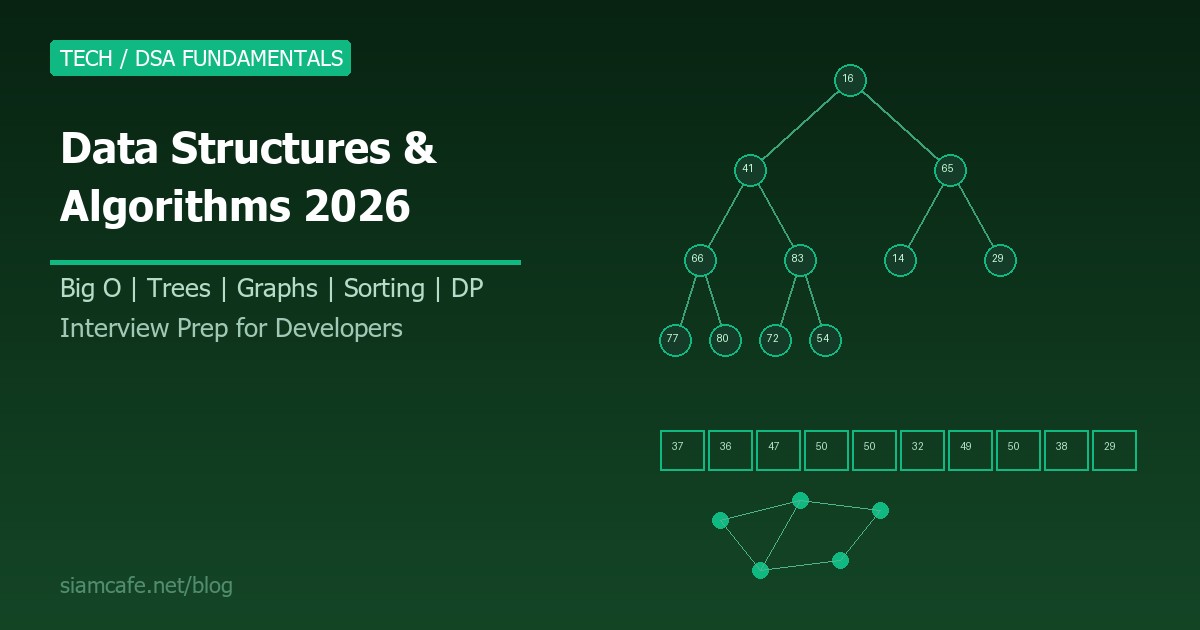
Binary Tree
Tree เป็น Data Structure แบบลำดับชั้น (Hierarchical) ที่แต่ละ Node มี Parent หนึ่งตัว (ยกเว้น Root) และ Children หลายตัว Binary Tree จำกัดให้แต่ละ Node มีลูกได้สูงสุด 2 ตัว (Left และ Right) ใช้ในระบบไฟล์ (Folder structure), DOM ของ HTML, Decision Tree ใน Machine Learning
เนื้อหาเกี่ยวข้อง — ดูเพิ่มเติมเรื่อง java constructor คือ
Binary Search Tree (BST)
BST คือ Binary Tree ที่มีกฎ: Node ฝั่งซ้ายมีค่าน้อยกว่า Node ปัจจุบัน และ Node ฝั่งขวามีค่ามากกว่า ทำให้ค้นหาข้อมูลได้เร็วเพียง O(log n) ในกรณีที่ Tree สมดุล
class TreeNode:
def __init__(self, val):
self.val = val
self.left = None
self.right = None
class BST:
def __init__(self):
self.root = None
def insert(self, val):
if not self.root:
self.root = TreeNode(val)
else:
self._insert(self.root, val)
def _insert(self, node, val):
if val < node.val:
if node.left is None:
node.left = TreeNode(val)
else:
self._insert(node.left, val)
else:
if node.right is None:
node.right = TreeNode(val)
else:
self._insert(node.right, val)
def search(self, val) -> bool:
return self._search(self.root, val)
def _search(self, node, val) -> bool:
if node is None:
return False
if val == node.val:
return True
elif val < node.val:
return self._search(node.left, val)
else:
return self._search(node.right, val)
def inorder(self):
"""Inorder Traversal — ได้ค่าเรียงจากน้อยไปมาก"""
result = []
self._inorder(self.root, result)
return result
def _inorder(self, node, result):
if node:
self._inorder(node.left, result)
result.append(node.val)
self._inorder(node.right, result)
# ใช้งาน
bst = BST()
for val in [50, 30, 70, 20, 40, 60, 80]:
bst.insert(val)
print(bst.search(40)) # True
print(bst.search(45)) # False
print(bst.inorder()) # [20, 30, 40, 50, 60, 70, 80]AVL Tree
AVL Tree คือ Self-Balancing BST ที่รักษาความสมดุลโดยให้ความสูงของ Subtree ซ้ายและขวาต่างกันไม่เกิน 1 เมื่อไม่สมดุลจะทำ Rotation เพื่อปรับ ทำให้ทุก Operation เป็น O(log n) เสมอ ไม่มี Worst Case O(n) เหมือน BST ธรรมดา Database Index ส่วนใหญ่ใช้ B-Tree ซึ่งเป็นแนวคิดคล้าย AVL แต่ปรับให้เหมาะกับ Disk I/O
Heaps และ Priority Queues

Heap เป็น Complete Binary Tree ที่มีคุณสมบัติพิเศษ: ใน Min-Heap Node แม่จะมีค่าน้อยกว่าหรือเท่ากับ Node ลูกเสมอ ใน Max-Heap กลับกัน ใช้ทำ Priority Queue ที่ดึงค่าต่ำสุด/สูงสุดได้ใน O(1) และเพิ่ม/ลบใน O(log n)
import heapq
# Min-Heap (Python heapq เป็น Min-Heap โดย default)
min_heap = []
heapq.heappush(min_heap, 30)
heapq.heappush(min_heap, 10)
heapq.heappush(min_heap, 20)
heapq.heappush(min_heap, 5)
print(heapq.heappop(min_heap)) # 5 — ค่าน้อยสุดออกก่อน
print(heapq.heappop(min_heap)) # 10
# ตัวอย่าง: หา K ตัวที่ใหญ่ที่สุด
def k_largest(nums: list, k: int) -> list:
return heapq.nlargest(k, nums)
print(k_largest([3, 1, 5, 12, 2, 11], 3)) # [12, 11, 5]
# Priority Queue สำหรับ Task Scheduling
tasks = []
heapq.heappush(tasks, (1, "Critical: Fix production bug"))
heapq.heappush(tasks, (3, "Low: Update documentation"))
heapq.heappush(tasks, (2, "Medium: Add unit tests"))
while tasks:
priority, task = heapq.heappop(tasks)
print(f"[Priority {priority}] {task}")
# [Priority 1] Critical: Fix production bug
# [Priority 2] Medium: Add unit tests
# [Priority 3] Low: Update documentationGraphs — กราฟ
Graph เป็น Data Structure ที่ประกอบด้วย Nodes (Vertices) และ Edges ที่เชื่อมต่อ Node เข้าด้วยกัน ต่างจาก Tree ตรงที่ Graph ไม่มีลำดับชั้น Node สามารถเชื่อมถึงกันได้อิสระ และอาจมี Cycle ใช้แทนเครือข่ายสังคม แผนที่ถนน Dependencies ของ Package และอีกมากมาย
แนะนำเพิ่มเติม — iCafeForex
from collections import defaultdict, deque
class Graph:
def __init__(self):
self.adjacency_list = defaultdict(list)
def add_edge(self, u, v):
self.adjacency_list[u].append(v)
self.adjacency_list[v].append(u) # Undirected graph
def bfs(self, start):
"""Breadth-First Search — ค้นหาแบบกว้าง (ระดับต่อระดับ)"""
visited = set()
queue = deque([start])
visited.add(start)
order = []
while queue:
node = queue.popleft()
order.append(node)
for neighbor in self.adjacency_list[node]:
if neighbor not in visited:
visited.add(neighbor)
queue.append(neighbor)
return order
def dfs(self, start):
"""Depth-First Search — ค้นหาแบบลึก (ดิ่งลงไปจนสุด)"""
visited = set()
order = []
self._dfs_recursive(start, visited, order)
return order
def _dfs_recursive(self, node, visited, order):
visited.add(node)
order.append(node)
for neighbor in self.adjacency_list[node]:
if neighbor not in visited:
self._dfs_recursive(neighbor, visited, order)
def shortest_path(self, start, end):
"""หาเส้นทางสั้นที่สุด (Unweighted) ด้วย BFS"""
visited = set()
queue = deque([(start, [start])])
visited.add(start)
while queue:
node, path = queue.popleft()
if node == end:
return path
for neighbor in self.adjacency_list[node]:
if neighbor not in visited:
visited.add(neighbor)
queue.append((neighbor, path + [neighbor]))
return None
# ใช้งาน
g = Graph()
g.add_edge("Bangkok", "Nonthaburi")
g.add_edge("Bangkok", "Samut Prakan")
g.add_edge("Nonthaburi", "Pathum Thani")
g.add_edge("Pathum Thani", "Ayutthaya")
g.add_edge("Samut Prakan", "Chonburi")
print("BFS:", g.bfs("Bangkok"))
print("DFS:", g.dfs("Bangkok"))
print("Shortest:", g.shortest_path("Bangkok", "Ayutthaya"))
# Shortest: ['Bangkok', 'Nonthaburi', 'Pathum Thani', 'Ayutthaya']| Algorithm | ใช้เมื่อ | Time Complexity |
|---|---|---|
| BFS | หาเส้นทางสั้นที่สุด (Unweighted), Level-order traversal | O(V + E) |
| DFS | ตรวจ Cycle, Topological Sort, Connected Components | O(V + E) |
| Dijkstra | เส้นทางสั้นที่สุด (Weighted, non-negative) | O((V+E) log V) |
Sorting Algorithms — การเรียงลำดับ
Bubble Sort — O(n^2)
เปรียบเทียบคู่ที่อยู่ติดกันแล้วสลับ ทำซ้ำจนเรียงหมด ง่ายที่สุดแต่ช้าที่สุด ใช้เพื่อการเรียนรู้เท่านั้น ไม่ควรใช้ในงานจริง
เนื้อหาเกี่ยวข้อง — อ่านต่อ: OPA Gatekeeper Kubernetes Deployment
def bubble_sort(arr):
n = len(arr)
for i in range(n):
swapped = False
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
swapped = True
if not swapped:
break # เรียงแล้ว ไม่ต้องทำต่อ
return arr
print(bubble_sort([64, 34, 25, 12, 22, 11, 90]))Merge Sort — O(n log n)
ใช้หลัก Divide and Conquer — แบ่งครึ่ง เรียงแต่ละครึ่ง แล้วรวมกลับ เสถียร (Stable) และรับประกัน O(n log n) เสมอ แต่ใช้ Memory เพิ่ม O(n)
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left = merge_sort(arr[:mid])
right = merge_sort(arr[mid:])
return merge(left, right)
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
print(merge_sort([38, 27, 43, 3, 9, 82, 10]))Quick Sort — O(n log n) เฉลี่ย
เลือก Pivot แบ่งข้อมูลเป็น 2 กลุ่ม (น้อยกว่า Pivot, มากกว่า Pivot) แล้ว Sort แต่ละกลุ่ม เร็วในทางปฏิบัติ ใช้ Memory น้อย แต่ Worst Case เป็น O(n^2) เมื่อเลือก Pivot ไม่ดี Python ใช้ Timsort (Merge Sort + Insertion Sort) ซึ่งเร็วกว่าในทางปฏิบัติ
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
print(quick_sort([3, 6, 8, 10, 1, 2, 1]))Counting Sort — O(n + k)
นับจำนวนครั้งที่แต่ละค่าปรากฏ ไม่ได้เปรียบเทียบค่า จึงเร็วมากถ้าช่วงค่า (k) ไม่กว้างเกินไป เหมาะกับข้อมูลจำนวนเต็มที่มีช่วงค่าจำกัด เช่น คะแนนสอบ 0-100 หรืออายุ
def counting_sort(arr):
if not arr:
return arr
max_val = max(arr)
count = [0] * (max_val + 1)
for num in arr:
count[num] += 1
result = []
for i, c in enumerate(count):
result.extend([i] * c)
return result
print(counting_sort([4, 2, 2, 8, 3, 3, 1]))Binary Search — ค้นหาแบบแบ่งครึ่ง
Binary Search ค้นหาใน Sorted Array ได้ใน O(log n) โดยเปรียบเทียบค่าตรงกลาง ถ้าค่าที่หาน้อยกว่าตรงกลาง ค้นครึ่งซ้าย ถ้ามากกว่า ค้นครึ่งขวา เหมือนเปิดพจนานุกรม — ไม่ต้องเปิดทุกหน้า แค่เปิดตรงกลางแล้วเทียบ
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1 # ไม่พบ
sorted_arr = [2, 5, 8, 12, 16, 23, 38, 56, 72, 91]
print(binary_search(sorted_arr, 23)) # 5 (index)
print(binary_search(sorted_arr, 50)) # -1 (ไม่พบ)
# ตัวอย่างจริง: หาตำแหน่งที่ควรแทรก
import bisect
arr = [1, 3, 5, 7, 9]
pos = bisect.bisect_left(arr, 6)
print(f"Insert 6 at index {pos}") # Insert 6 at index 3Dynamic Programming (DP) — โปรแกรมพลวัต
Dynamic Programming แก้ปัญหาโดยแบ่งเป็นปัญหาย่อยที่ซ้ำกัน (Overlapping Subproblems) แล้วเก็บผลลัพธ์ไว้ใช้ซ้ำ (Memoization) แทนที่จะคำนวณซ้ำ ลด Time Complexity จาก Exponential เป็น Polynomial ได้
# Fibonacci — แบบ Naive O(2^n)
def fib_naive(n):
if n <= 1:
return n
return fib_naive(n - 1) + fib_naive(n - 2)
# Fibonacci — แบบ DP (Memoization) O(n)
def fib_memo(n, memo={}):
if n in memo:
return memo[n]
if n <= 1:
return n
memo[n] = fib_memo(n - 1, memo) + fib_memo(n - 2, memo)
return memo[n]
# Fibonacci — แบบ DP (Bottom-up) O(n), Space O(1)
def fib_dp(n):
if n <= 1:
return n
a, b = 0, 1
for _ in range(2, n + 1):
a, b = b, a + b
return b
print(fib_dp(50)) # 12586269025 — ตอบทันที
# ตัวอย่าง: Climbing Stairs (โจทย์สัมภาษณ์ยอดนิยม)
def climb_stairs(n: int) -> int:
"""มีกี่วิธีขึ้นบันได n ขั้น ถ้าก้าวได้ 1 หรือ 2 ขั้น"""
if n <= 2:
return n
a, b = 1, 2
for _ in range(3, n + 1):
a, b = b, a + b
return b
print(climb_stairs(10)) # 89 วิธี
# ตัวอย่าง: 0/1 Knapsack Problem
def knapsack(weights, values, capacity):
n = len(weights)
dp = [[0] * (capacity + 1) for _ in range(n + 1)]
for i in range(1, n + 1):
for w in range(capacity + 1):
if weights[i-1] <= w:
dp[i][w] = max(
dp[i-1][w],
dp[i-1][w - weights[i-1]] + values[i-1]
)
else:
dp[i][w] = dp[i-1][w]
return dp[n][capacity]
weights = [2, 3, 4, 5]
values = [3, 4, 5, 6]
capacity = 8
print(f"Max value: {knapsack(weights, values, capacity)}") # Max value: 10Greedy Algorithms — อัลกอริทึมแบบละโมบ
Greedy Algorithm ตัดสินใจเลือกสิ่งที่ดีที่สุดในแต่ละขั้นตอน (Local Optimal) โดยหวังว่าจะนำไปสู่ผลลัพธ์ที่ดีที่สุดโดยรวม (Global Optimal) ไม่ได้ให้ผลลัพธ์ที่ดีที่สุดเสมอ แต่ใช้ได้กับปัญหาบางประเภท
เนื้อหาเกี่ยวข้อง — ดูเพิ่มเติมเรื่อง Terraform State Infrastructure as Code
# ตัวอย่าง: Activity Selection — เลือกกิจกรรมที่ทำได้มากที่สุด
def activity_selection(activities):
"""activities = [(start, end), ...]"""
# เรียงตามเวลาจบ
sorted_acts = sorted(activities, key=lambda x: x[1])
selected = [sorted_acts[0]]
for act in sorted_acts[1:]:
if act[0] >= selected[-1][1]: # ไม่ทับกัน
selected.append(act)
return selected
activities = [(1, 4), (3, 5), (0, 6), (5, 7), (3, 9), (5, 9), (6, 10), (8, 11)]
result = activity_selection(activities)
print(f"Selected {len(result)} activities: {result}")
# Selected 4 activities: [(1, 4), (5, 7), (8, 11)] หรือใกล้เคียง
# ตัวอย่าง: Coin Change (Greedy — ใช้ได้เฉพาะ coin set บางแบบ)
def coin_change_greedy(amount, coins):
coins.sort(reverse=True)
result = []
for coin in coins:
while amount >= coin:
result.append(coin)
amount -= coin
return result if amount == 0 else None
print(coin_change_greedy(93, [1, 5, 10, 25]))
# [25, 25, 25, 10, 5, 1, 1, 1]Time/Space Complexity Cheat Sheet
| Data Structure | Access | Search | Insert | Delete | Space |
|---|---|---|---|---|---|
| Array | O(1) | O(n) | O(n) | O(n) | O(n) |
| Linked List | O(n) | O(n) | O(1) | O(1) | O(n) |
| Stack/Queue | O(n) | O(n) | O(1) | O(1) | O(n) |
| Hash Table | N/A | O(1)* | O(1)* | O(1)* | O(n) |
| BST (balanced) | O(log n) | O(log n) | O(log n) | O(log n) | O(n) |
| Heap | O(1)** | O(n) | O(log n) | O(log n) | O(n) |
* Average case, ** Min/Max only
| Sorting Algorithm | Best | Average | Worst | Space | Stable? |
|---|---|---|---|---|---|
| Bubble Sort | O(n) | O(n^2) | O(n^2) | O(1) | Yes |
| Merge Sort | O(n log n) | O(n log n) | O(n log n) | O(n) | Yes |
| Quick Sort | O(n log n) | O(n log n) | O(n^2) | O(log n) | No |
| Counting Sort | O(n+k) | O(n+k) | O(n+k) | O(k) | Yes |
| Timsort (Python) | O(n) | O(n log n) | O(n log n) | O(n) | Yes |
แพลตฟอร์มฝึกฝนและเตรียมสัมภาษณ์งาน
การเรียนรู้ DSA จากทฤษฎีอย่างเดียวไม่เพียงพอ ต้องฝึกแก้โจทย์จริงด้วย ต่อไปนี้คือแพลตฟอร์มที่ดีที่สุดในปี 2026 สำหรับการฝึกฝน
| แพลตฟอร์ม | จุดเด่น | เหมาะสำหรับ |
|---|---|---|
| LeetCode | โจทย์มากที่สุด (3,000+) แบ่งเป็น Easy/Medium/Hard มีสถิติบริษัท | เตรียมสัมภาษณ์โดยเฉพาะ FAANG |
| HackerRank | หลักสูตรเป็นลำดับขั้น มี Certification วัดระดับ | ผู้เริ่มต้นที่อยากเรียนเป็นลำดับ |
| CodeSignal | บริษัทหลายแห่งใช้เป็นเครื่องมือสอบ มี Assessment แบบจริง | เตรียมตัวก่อนสอบจริง |
| NeetCode | รวมโจทย์ 150 ข้อที่สำคัญที่สุด พร้อมคำอธิบายวิดีโอ | คนที่มีเวลาจำกัด ต้องการโจทย์คุณภาพ |
| Codeforces | แข่ง Competitive Programming มีโจทย์ท้าทายมาก | คนที่อยากไปไกลกว่าสัมภาษณ์งาน |
กลยุทธ์เตรียมสัมภาษณ์งาน DSA
- เรียนทฤษฎีก่อน (สัปดาห์ที่ 1-2): เข้าใจ Big O, เรียนรู้ Data Structure แต่ละประเภท เน้นเข้าใจว่าแต่ละตัวเหมาะกับปัญหาแบบไหน ไม่ต้องท่องจำโค้ด
- ทำโจทย์ Easy 50 ข้อ (สัปดาห์ที่ 3-4): เริ่มจากโจทย์ง่ายเพื่อสร้างความมั่นใจ ฝึก Pattern การคิด เช่น Two Pointer, Sliding Window, Hash Map
- ทำโจทย์ Medium 50 ข้อ (สัปดาห์ที่ 5-8): โจทย์ระดับนี้เป็นระดับที่สัมภาษณ์จริงมักถาม เน้น Trees, Graphs, DP เบื้องต้น
- ทำโจทย์ Hard 20 ข้อ (สัปดาห์ที่ 9-10): สำหรับตำแหน่ง Senior หรือบริษัทชั้นนำ ไม่ต้องแก้ได้ทุกข้อ แต่ต้องเข้าใจแนวคิด
- Mock Interview (สัปดาห์ที่ 11-12): ฝึกพูดอธิบายความคิดขณะเขียนโค้ด (Think Aloud) ฝึกถามคำถามชี้แจง (Clarifying Questions) และวิเคราะห์ Time/Space Complexity
สรุป
Data Structures และ Algorithms เป็นพื้นฐานที่ไม่เคยล้าสมัย ไม่ว่าภาษาโปรแกรมหรือ Framework จะเปลี่ยนไปอย่างไร หลักการของ DSA ยังคงใช้ได้เสมอ การเข้าใจว่าเมื่อไหร่ควรใช้ Array เมื่อไหร่ควรใช้ Hash Table เมื่อไหร่ควรใช้ Tree จะทำให้คุณเป็น Developer ที่เขียนโค้ดได้อย่างมีประสิทธิภาพ
เริ่มต้นวันนี้ด้วยการเปิด LeetCode ทำโจทย์ Easy วันละ 1 ข้อ ภายใน 2-3 เดือน คุณจะรู้สึกว่าทุกปัญหาการเขียนโค้ดมีรูปแบบที่คุ้นเคย และคุณสามารถเลือกเครื่องมือที่เหมาะสมในการแก้ปัญหาได้อย่างมั่นใจ DSA ไม่ใช่แค่สิ่งที่ต้องรู้เพื่อสัมภาษณ์งาน แต่เป็นทักษะที่จะทำให้คุณเป็น Developer ที่ดีขึ้นในทุกๆ วัน