Computer Vision YOLO Testing Strategy QA — คู่มือฉบับสมบูรณ์ 2026

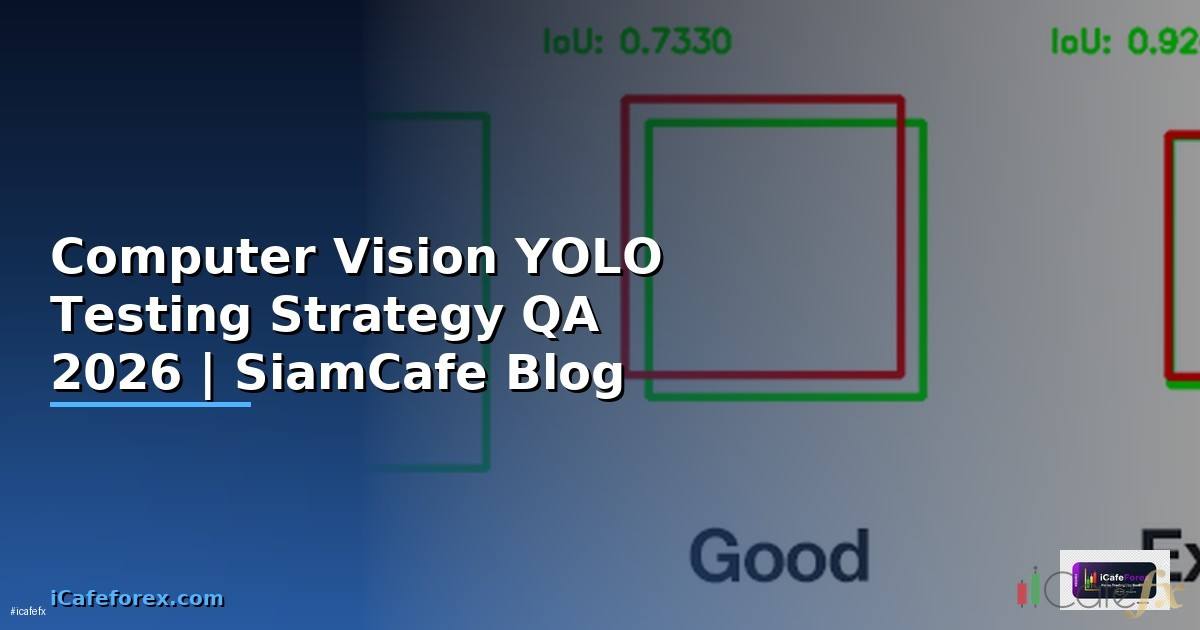
Computer Vision YOLO Testing Strategy QA คืออะไร

YOLO (You Only Look Once) เป็น real-time object detection model ที่ได้รับความนิยมสูงสุดในด้าน computer vision สามารถตรวจจับวัตถุหลายชนิดในภาพเดียวด้วยความเร็วสูง Testing Strategy QA สำหรับ YOLO คือกระบวนการทดสอบและประกันคุณภาพของ model ตั้งแต่ data quality, model accuracy, inference performance ไปจนถึง edge cases และ production monitoring เพื่อให้มั่นใจว่า model ทำงานได้ถูกต้องและเชื่อถือได้ในสภาพแวดล้อมจริง

FAQ - คำถามที่พบบ่อย
Q: mAP เท่าไหร่ถึงจะดีพอสำหรับ production?
A: ขึ้นอยู่กับ use case Safety-critical (self-driving): mAP@50 > 95% General object detection: mAP@50 > 75% Prototype/MVP: mAP@50 > 60% สิ่งสำคัญกว่า mAP: per-class performance, false positive rate, edge cases
เนื้อหาเกี่ยวข้อง — แนะนำให้อ่าน PagerDuty Incident Pod Scheduling — จัดการ
Q: YOLOv8 กับ YOLOv5 อันไหนดี?
แนะนำเพิ่มเติม — iCafeForex
A: YOLOv8: ใหม่กว่า, accuracy ดีกว่า, API ง่ายกว่า (Ultralytics), anchor-free YOLOv5: stable, community ใหญ่, documentation เยอะ แนะนำ: ใช้ YOLOv8 สำหรับ projects ใหม่ เว้นแต่มี legacy YOLOv5 ที่ทำงานดีอยู่แล้ว
เนื้อหาเกี่ยวข้อง — ดูเพิ่มเติมเรื่อง หุ้น บัวหลวง กับเทรนด์เทคโนโลยีใหม่: โอกาสการลงทุนในยุคดิจิทัล
Q: Test data ต้องเตรียมอย่างไร?
A: แยก train/val/test: 70/15/15 หรือ 80/10/10 Test set ต้องไม่ overlap กับ train set เลย Test set ควรครอบคลุม edge cases (dark, blur, occlusion) ตรวจ class balance ใน test set ใช้ stratified split เพื่อให้ class distribution เท่ากัน
แนะนำเพิ่มเติม — ติดตาม XM Signal
เนื้อหาเกี่ยวข้อง — ดูเพิ่มเติมเรื่อง market automation คือ
Q: Model drift ตรวจอย่างไร?
A: Compare accuracy metrics เป็น periodic (weekly/monthly) Monitor confidence score distribution (ถ้าลดลง = drift) Sample production predictions → human review (spot check) Re-evaluate กับ fresh labeled data A/B test model versions ใน production
เนื้อหาเกี่ยวข้อง — ทำความเข้าใจ Prometheus Federation Cache Strategy Redis





