BigQuery Scheduled Query — ตั้งเวลารัน Query อัตโนมัติ
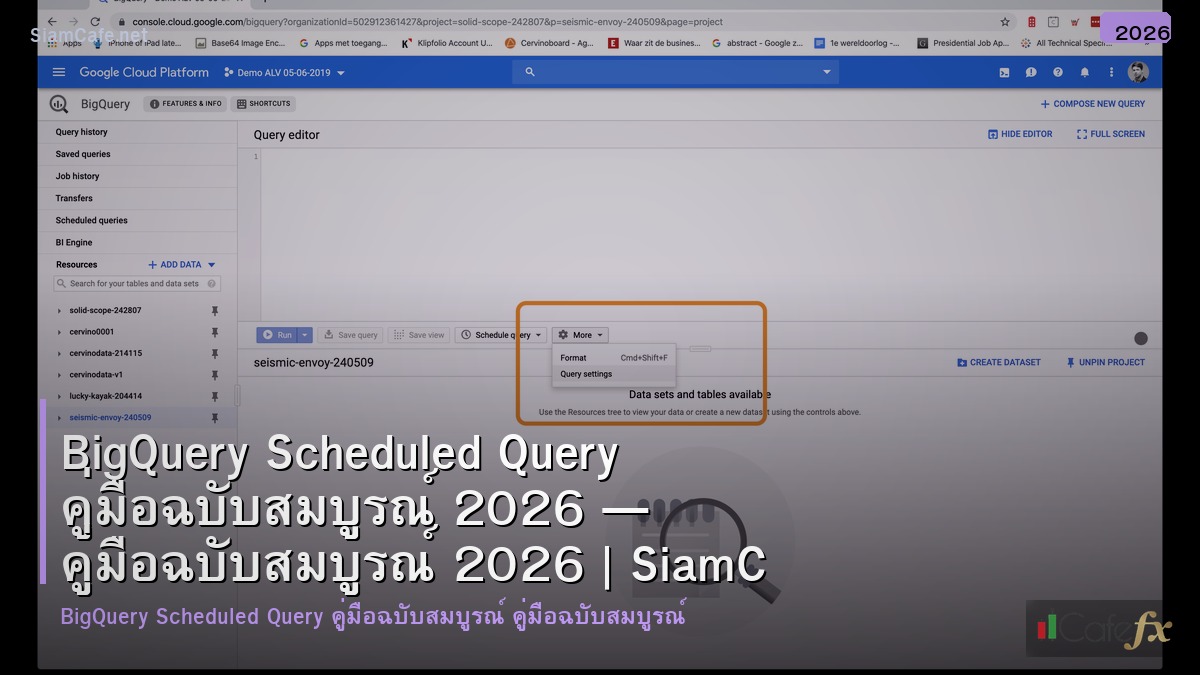

BigQuery Scheduled Query
BigQuery Scheduled Query ตั้งเวลา SQL อัตโนมัติ ETL Pipeline Report Aggregation Cost Optimization Production
| Feature | Scheduled Query | Dataform | Cloud Composer |
|---|---|---|---|
| Complexity | ง่าย (single query) | กลาง (SQL workflow) | สูง (full DAG) |
| Dependencies | ไม่รองรับ | รองรับ (ref()) | Full DAG support |
| Version Control | ไม่มี | Git integration | Git + Airflow |
| Cost | ฟรี (จ่ายแค่ Query) | ฟรี (จ่ายแค่ Query) | $300+/เดือน (VM) |
| Best For | Simple ETL, reports | dbt-like SQL pipelines | Complex multi-system |
เคล็ดลับ
- Partition: ใช้ Partitioned Table + WHERE date ลด Cost 50-90%
- Parameter: ใช้ @run_date @run_time สำหรับ Dynamic Date
- Alert: ตั้ง Pub/Sub + Cloud Function แจ้งเตือน Slack เมื่อ Fail
- Dry Run: ตรวจ Cost ด้วย Dry Run ก่อน Schedule ทุกครั้ง
- Terraform: ใช้ Terraform จัดการ Scheduled Query เป็น Code
การบริหารจัดการฐานข้อมูลอย่างมืออาชีพ

Database Management ที่ดีเริ่มจากการออกแบบ Schema ที่เหมาะสม ใช้ Normalization ลด Data Redundancy สร้าง Index บน Column ที่ Query บ่อย วิเคราะห์ Query Plan เพื่อ Optimize Performance และทำ Regular Maintenance เช่น VACUUM สำหรับ PostgreSQL หรือ OPTIMIZE TABLE สำหรับ MySQL
เรื่อง High Availability ควรติดตั้ง Replication อย่างน้อย 1 Replica สำหรับ Read Scaling และ Disaster Recovery ใช้ Connection Pooling เช่น PgBouncer หรือ ProxySQL ลดภาระ Connection ที่เปิดพร้อมกัน และตั้ง Automated Failover ให้ระบบสลับไป Replica อัตโนมัติเมื่อ Primary ล่ม
เนื้อหาเกี่ยวข้อง — unemployment claims คือ
Backup ต้องทำทั้ง Full Backup รายวัน และ Incremental Backup ทุก 1-4 ชั่วโมง เก็บ Binary Log หรือ WAL สำหรับ Point-in-Time Recovery ทดสอบ Restore เป็นประจำ และเก็บ Backup ไว้ Off-site ด้วยเสมอ
แนะนำเพิ่มเติม — บทวิเคราะห์จาก XM Signal
Scheduled Query คืออะไร
ตั้งเวลา SQL อัตโนมัติ ทุกวัน ชั่วโมง สัปดาห์ ETL Report Quality Aggregation Console CLI API Terraform Notification Email
เนื้อหาเกี่ยวข้อง — Payload CMS Interview Preparation
ตั้งค่าอย่างไร
Console SQL Schedule Repeat Destination WRITE_TRUNCATE APPEND Service Account @run_date @run_time Notification bq CLI Terraform
Error Handling ทำอย่างไร
Email Notification Pub/Sub Cloud Function Run History Retry Service Account Permission Destination Table Quota Cloud Monitoring Alert
แนะนำเพิ่มเติม — SiamCafeBook
เนื้อหาเกี่ยวข้อง — แนะนำให้อ่าน flutter container คือ
ประหยัดค่าใช้จ่ายอย่างไร
Partitioned Table Clustered SELECT เฉพาะ Column Schedule เหมาะสม Materialized View Reservation Dry Run BI Engine Cache
สรุป
BigQuery Scheduled Query ETL Pipeline Automation Schedule Pattern Error Handling Cost Optimization Partition Clustering Terraform Production
เนื้อหาเกี่ยวข้อง — บทความที่เกี่ยวข้อง: Header PHP คืออะไร? คู่มือฉบับสมบูรณ์ 2026 สำหรับนักพัฒนาเว็บไซต์





