ai
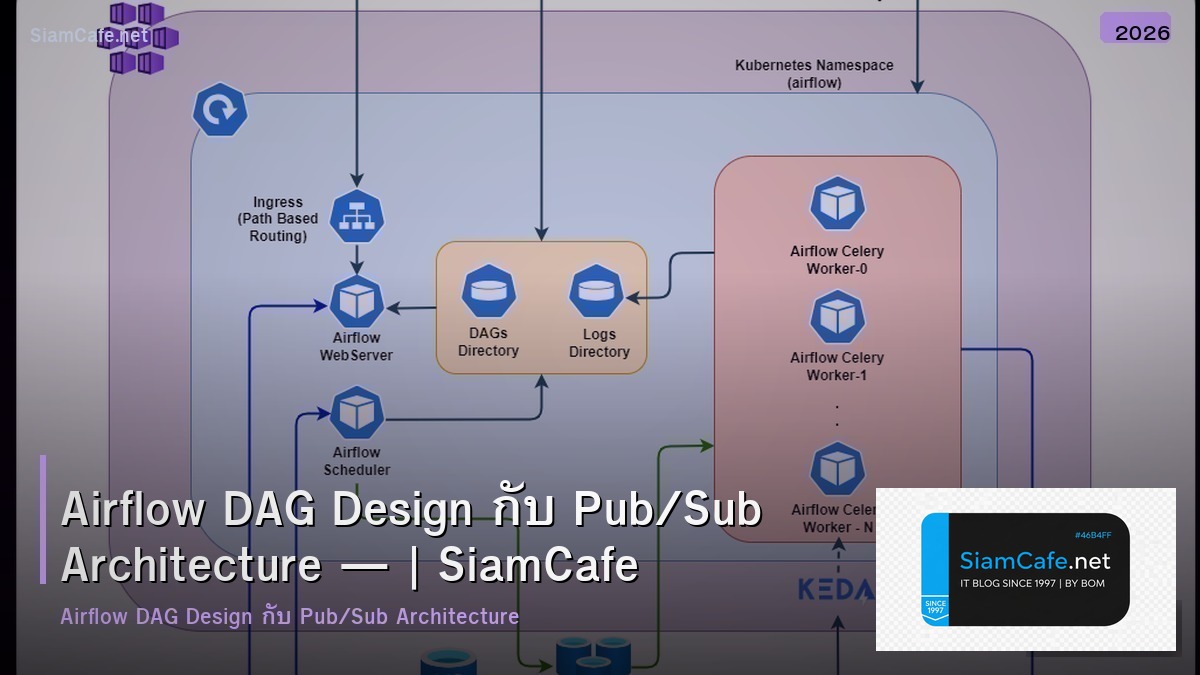
Airflow DAG Design กับ Pub/Sub Architecture —

Airflow DAG กับ Pub/Sub

Airflow DAG กำหนดลำดับ Tasks แต่ละ Task มี Dependencies Airflow จัดการ Schedule Retry Monitoring Pub/Sub ช่วยทำ Event-driven Trigger DAG อัตโนมัติ
เนื้อหาเกี่ยวข้อง — WordPress Headless Container Orchestration
DAG Design Patterns Sequential Parallel Branch Dynamic Sensor-triggered ออกแบบให้เหมาะกับ Data Pipeline
แนะนำเพิ่มเติม — ระบบเทรดของ iCafeForex
เนื้อหาเกี่ยวข้อง — ดูเพิ่มเติมเรื่อง elliott corrective wave
เนื้อหาเกี่ยวข้อง — แนะนำให้อ่าน Eleventy Static High Availability HA Setup
Production Configuration
# === Airflow Production Configuration ===
# 1. airflow.cfg — Key Settings
# [core]
# executor = CeleryExecutor # Production executor
# parallelism = 32 # Max concurrent tasks
# max_active_runs_per_dag = 3 # Max concurrent DAG runs
# dag_file_processor_timeout = 120 # Seconds to parse DAG file
#
# [celery]
# broker_url = redis://redis:6379/0
# result_backend = redis://redis:6379/1
# worker_concurrency = 16
#
# [scheduler]
# min_file_process_interval = 30 # Seconds between DAG file scans
# dag_dir_list_interval = 300 # Seconds between dir scans
#
# [webserver]
# web_server_port = 8080
# default_ui_timezone = Asia/Bangkok
# 2. Docker Compose — Production
# version: '3.8'
# services:
# postgres:
# image: postgres:16
# environment:
# POSTGRES_USER: airflow
# POSTGRES_PASSWORD: airflow
# POSTGRES_DB: airflow
#
# redis:
# image: redis:7-alpine
#
# airflow-webserver:
# image: apache/airflow:2.8.1
# command: webserver
# ports: ["8080:8080"]
# depends_on: [postgres, redis]
#
# airflow-scheduler:
# image: apache/airflow:2.8.1
# command: scheduler
# depends_on: [postgres, redis]
#
# airflow-worker:
# image: apache/airflow:2.8.1
# command: celery worker
# depends_on: [postgres, redis]
# deploy:
# replicas: 3
# 3. Pool Configuration
# airflow pools set default_pool 32 "Default pool"
# airflow pools set heavy_tasks 4 "CPU/Memory intensive tasks"
# airflow pools set api_calls 8 "External API rate limited"
# airflow pools set db_queries 16 "Database query tasks"
# 4. Connection Configuration
# airflow connections add 'kafka_default' \
# --conn-type 'kafka' \
# --conn-host 'kafka:9092' \
# --conn-extra '{"security.protocol": "SASL_SSL"}'
# 5. Monitoring — Prometheus + Grafana
# pip install apache-airflow[statsd]
# [metrics]
# statsd_on = True
# statsd_host = statsd-exporter
# statsd_port = 8125
production_config = {
"Executor": "CeleryExecutor (Redis broker)",
"Workers": "3 replicas, 16 concurrency each",
"Pools": "default(32), heavy(4), api(8), db(16)",
"Database": "PostgreSQL 16",
"Cache": "Redis 7",
"Monitoring": "Prometheus + Grafana + StatsD",
"Logging": "S3/GCS remote logging",
}
print("Production Configuration:")
for key, value in production_config.items():
print(f" {key}: {value}")Best Practices

- TaskGroup: ใช้ TaskGroup แทน SubDAG จัดกลุ่ม Tasks
- Sensor Mode: ใช้ mode="reschedule" ประหยัด Worker Slot
- @task Decorator: ใช้ @task แทน PythonOperator เขียนสั้นกว่า
- Pools: ตั้ง Pool จำกัด Concurrent Tasks ป้องกัน Overload
- Idempotent: ทำ Tasks ให้ Idempotent รันซ้ำได้ผลเหมือนเดิม
- SLA: ตั้ง SLA สำหรับ Critical DAGs แจ้งเตือนเมื่อช้ากว่ากำหนด
Airflow DAG คืออะไร
Directed Acyclic Graph Workflow Apache Airflow ลำดับ Tasks Dependencies ชัดเจน ไม่ Circular Airflow Schedule Retry Monitoring อัตโนมัติ เขียน Python
แนะนำเพิ่มเติม — XM Signal
เนื้อหาเกี่ยวข้อง — อ่านต่อ: Calico Network Policy Performance Tuning





